이 글은 아래 사이트의 내용을 정리한 글입니다.
colah.github.io/posts/2015-08-Understanding-LSTMs/
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
1. LSTM이란?
- LSTM(Long Short Term Memory networks)는 RNN의 줄임말로 Vanishing gradient(exploding gradient) 문제와 단어간의 사이가 멀어질수록 잘 기억을 하지 못하는 'long term dependency(장기 의존성)' 문제를 해결하기 위하여 제안된 RNN의 특별한 유형중 하나입니다.
- 1997년 처음 Hochreiter & Schmidhuber 에 의하여 소개된 이후 많은 사람들에 의하여 가공되고 유명해졌으며, 현재 광범위하게 사용되고 있습니다.
| ※ long-term dependency (장기 의존성)이란? : 시퀀스 데이터의 길이가 길어질수록, 과거의 중요한 정보에 대한 학습이 어려워지는 문제 (가만 두자니 vanishing gradient, gradient를 좀 올려보자니 exploding gradient 발생) : 이 문제를 해결하기 위해서 두가지 접근이 존재함 (1) stochastic gradient descent(SGD) 방법으로 대체 (2) LSTM과 GRU와 같은 더 세련된 RNN모델 고안 |
2. LSTM의 구조
2.1 기본 RNN vs LSTM
: LSTM의 구조는 기본 RNN과 같이 체인처럼 이어져있는(chain-like) 모양이지만, 아주 특별한 방식으로 상호작용하는4개의 길(cell state, forget gate, input gate, output gate)이 있습니다.
: LSTM은 RNN과 다르게 화살표로 나타나는 상태(state)이 2개(cell-state, hidden-state)로 되어있습니다. cell-state를 C(t)라고 표기하며 장기 상태(long term state)이라고 하며, hidden-state를 h(t)라고 표기하며 단기상태(short term state)라고 합니다.


2.2 RNN에는 없지만 LSTM에 등장한 요소
(1) Cell state 란?
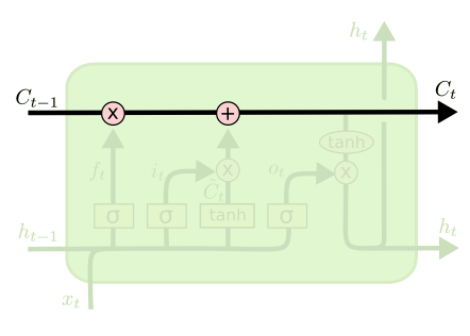
- LSTM의 핵심은 모델 구조도에서 위의 수평선에 해당하는 cell state입니다. cell state는 컨베이어 벨트와 같은 역할로 전체 체인을 지나면서, 일부 선형적인 상호작용만을 진행합니다. 정보가 특별한 변화 없이 흘러가는 것으로 이해하면 쉽습니다.
- LSTM에서 cell state를 업데이트하는 것이 가장 중요 한 일이며, 'gate라는 구조가 cell state에 정보를 더하거나 제거하는 조절 기능을 합니다.
(2) 'Gate' 란?

= 'sigmoid layer outputs'+'pointwise multiplication operation'
- gate란 정보를 선택적으로 통과시키는 길로, 시그모이드 뉴럴 네트워크 층과 접곱(point wise multiplication) 연산으로 이루어져있습니다.
- LSTM은 cell state를 조절하고 보호하기 위하여 총 3개의 gate(forget, input, output)를 갖습니다.
- 시그모이드 층은 0과 1사이의 값을 출력하는데, 이 값들은 각 원소들을 얼마나 많이 통과시킬 것인지를 의미합니다. 예를들어 숫자 '0'은 어떤것도 통과시키지 않음을 의미하며, 숫자 '1'은 모든 것을 통과시킴을 의미합니다.
3. LSTM 진행 단계
[STEP1] Forget gate
- LSTM의 첫번째 단계는, cell state에서 어떤 정보를 버릴 것인가를 결정하는 것이며, 이것은 "forget gate layer"의 시그모이드 층에서 결정됩니다.

- Forget gate에서는 이전 hidden 값 h(t-1)과 현재 입력값 x(t)를 확인하고 이전 cell state C(t-1)에 있는 각 요소에 대해서 0과 1사이의 값을 생성합니다. 숫자 '1'은 "완벽히 보존"을 의미하고 '0'은 "완벽히 제거"를 의미합니다.
- 이 값은 최종 C(t)를 결정할때, C(t-1)과 곱해지는 값으로 이전의 cell state 정보(C(t))를 얼마나 통과시킬지를 결정합니다.
[STEP2] Input gate
- Input gate에서는 어떤 새로운 정보를 cell state에 저장/추가할 것인가하는 업데이트 정보를 결정합니다.

- 여기에는 두가지 파트가 있습니다.
1) "input gate layer" 이라고 불리는 시그모이드 층에서 어떤 값을 업데이트할지 결정
2) tanh 층에서는 state에 추가될 수 있는 새로운 후보 값(벡터, 틸다C(t)) 를 생성합니다.
[STEP3] Cell state 업데이트
- 이제 오래된 cell state C(t-1)을 새로운 cell stat인 C(t)로 업데이트할 차례입니다.
- 전 단계에서 무엇을 할지(어떤것을 잊을지, 어떤것을 새롭게 업데이트할지)는 이미 결정하였으니 이제 실제로 그것을 하기만 하면 됩니다!


1) [forget layer] 오래된 cell state C(t-1)에 f(t)를 곱하여, 잊기로 했던 것들을 잊기!
2) [input layer] i(t)*C'(t) --> C(t)의 후보
[STEP4] Ouptut gate
- 마지막으로 우리는 무엇을 출력(output)할지 결정해야합니다. 이 출력은 현재 cell state인 C(t)를 가지고 정하지만, 모든 C(t)를 사용하지 않고, 일부만 필터링하여 출력할 것입니다.

(1) 첫째로, 우리는 시그모이드 층을 써서 현재 cell state 중에서 어떤 부분만 출력을 할지를 정합니다. -> o(t)
(2) 둘째로, 우리는 cell state를 tanh 함수(-1과 1사이의 값을 출력)를 사용하고 위에서 구한 o(t)와 곱하여 최종적으로 출력할 부분을 결정합니다.
<LSTM 한 그림 요약>

- 기존의 RNN과 비교하자면, RNN에서는 cell state에 해당하는 C(t)가 없었고, h(t)만이 존재했습니다. RNN에서의 h(t)가 사실은 LSTM에서는 g(t) 즉, 틸다C(t)에 해당합니다.
- g(t)만 필요했던 RNN에 비해서 LSTM은 input 양을 조절하는 i(t), foget 양을 조절하는 f(t), output 양을 조절하는 o(t)까지 총 3개의 파라미터가 더 필요한 셈이죠. 정리하면, LSTM은 RNN에 비하여 파라미터가 1개에서 4개로 늘어나 4배가 더 필요하게 되었다고 할 수 있습니다.
4. Conclusion
- 이전에 RNN을 통해 사람들이 해결한 주목할만한 결과들에 대해서 언급을 한적이 있었습니다. 사실 그중 거의 모든 것은 LSTM을 사용하면서 성취한 것들입니다. 확실히 대부분의 작업에서 더 성능이 좋습니다.
- LSTM은 RNN에 있어서 우리가 성취해야할 큰 걸음마 중 하나였습니다. 우리에게 다음 스텝이 있을까요? 연구자들의 공통된 대답은 "Yes, It's attention" 입니다. attention의 아이디어는 RNN의 모든 스텝에서, 정보의 더 큰 모음에서 바라볼 수 있는 또 다른 정보를 고르게 하는 것입니다. 예를 들어, RNN을 사용하여 이미지 캡션을 생성할 때 생성하는 모든 단어를 보기위해서 일부의 이미지만을 선택할 것입니다(사실 Xu, et al. (2015)가 해당 연구를 진행하였습니다).
다음 글에서는 다소 복잡한 LSTM의 구조를 단순화시킨 GRU에 대해서 알아보도록 하겠습니다.
2021.05.10 - [딥러닝(Deep learning)] - [딥러닝 기초] GRU(Gated Recurrent Unit)
[딥러닝 기초] GRU(Gated Recurrent Unit)
hyen4110.tistory.com
[그 외]
1. RNN과 LSTM의 퇴락(?) 을 주제로 쓴 블로그: LSTM의 문제점을 재밌게 읽기 좋을듯
https://towardsdatascience.com/the-fall-of-rnn-lstm-2d1594c74ce0
The fall of RNN / LSTM
We fell for Recurrent neural networks (RNN), Long-short term memory (LSTM), and all their variants. Now it is time to drop them!
towardsdatascience.com
'AI > 딥러닝 기초(Deep learning)' 카테고리의 다른 글
| [딥러닝][NLP] Bidirectional RNN (0) | 2021.05.12 |
|---|---|
| [딥러닝] GRU(Gated Recurrent Unit) (1) | 2021.05.10 |
| [딥러닝][NLP] RNN(Recurrent Neural Network) (0) | 2021.05.07 |
| [딥러닝][기초] 모멘텀(Momentum) (0) | 2021.04.29 |
| [딥러닝][기초] 학습률(Learning rate)와 스케줄링 (0) | 2021.04.29 |




댓글