아래 2개의 페이지를 정리한 글입니다.
An intuitive guide to Convolutional Neural Networks
by Daphne Cornelisse An intuitive guide to Convolutional Neural NetworksPhoto by Daniel Hjalmarsson on UnsplashIn this article, we will explore Convolutional Neural Networks (CNNs) and, on a high level, go through how they are inspired by the structure of
www.freecodecamp.org
cs231n.github.io/convolutional-networks/#layerpat
CS231n Convolutional Neural Networks for Visual Recognition
Table of Contents: Convolutional Neural Networks (CNNs / ConvNets) Convolutional Neural Networks are very similar to ordinary Neural Networks from the previous chapter: they are made up of neurons that have learnable weights and biases. Each neuron receive
cs231n.github.io
1. 합성곱 신경망 (CNN, Convolutional Neural Networks)
1.1 일반적인 뉴럴 네트워크와 무엇이 다를까?
: 합성곱 신경망 CNN은 일반적인 뉴럴네트워크와 아주 유사합니다. 뉴런과 학습 가능한 가중치와 편향으로 구성되어있고, 각 뉴런은 입력값들을 받아서 곱(dot product)하며 비선형성을 따릅니다. 또 마지막 층에는 손실함수(Loss funtion)가 있으며, 일반적인 뉴럴 네트워크를 학습하기 위해 고안한 팁과 트릭들도 여전히 적용 가능합니다.
: 그렇다면 무엇이 다를까요? CNN은 '입력값이 이미지이다' 라는 명시적인 가정이 들어갑니다. 이것은 아키텍처에 특정 속성을 인코딩 할 수 있게 하며 전체 네트워크의 파라미터스를 급격히 줄이는데 매우 효과적입니다.
1) 일반적인 뉴럴 네트워크
: 뉴럴 네트워크에 대해서 다시 복습해볼까요? 뉴럴 네트워크는 입력값(single vector)을 받아서 은닉층을 거쳐서 변환시킵니다. 매 은닉층은 뉴런의 집합으로 구성되어있으며 각 뉴런은 이전 층의 모든 뉴런과 완전 연결(fully connected) 되어 있습니다. 마지막으로 완전 연결된(fully connected) 뉴런은 출력층(output layer)이라고 불리며 분류 문제에서는 각 class 점수를 나타냅니다.
: 사실, 일반적인 뉴럴 네트워크는 이미지(full image) 데이터에는 잘 맞지 않습니다. 예를들어, CIFAR-10*에서 이미지는 32x32x3(32 wide, 32 high, 3 color channels)이기 때문에 일반적인 뉴럴네트워크에서 첫 은닉층에 있는 완전 연결(fully connected) 뉴런은 32*32*3 = 3,072개의 가중치를 갖습니다. 숫자가 아직까지는 괜찮아 보입니다. 하지만, 200x200x3 사이즈의 이미지라면 어떨까요? 이때 뉴런은 200*200*3 = 12만 개의 가중치가 필요합니다. 이처럼 완전 연결(fully connectivity)이라는 특성은 효율적이지 않고(wasteful), 아주 많은 파라미터수는 빠른 오버피팅으로 이어진다는 한계점이 있습니다.
(*CIFAR-10: 일반적으로 머신 러닝 및 컴퓨터 비전 알고리즘을 훈련시키는 데 사용되는 이미지 모음)
| [요약] 일반적인 뉴럴네트워크의 한계점 |
| 1. 이미지를 입력값으로 받을 때, 파라미터수가 많이 필요함(오버피팅 발생 가능성 높음) 2. 중복된 이미지의 정보가 많을 수 있음 3. 픽셀이 하나만 이동(shift)하더라도 다른 이미지로 해석 4. 이미지 내의 특징이 어디에 위치하느냐에 따라 동일하게 해석하지 못함 |
2) 합성곱신경망(CNN)
: 합성곱신경망은 입력 데이터가 이미지로 이루어졌다는 가정을 바탕으로 이루어졌기 때문에 아키텍처를 더 합리적으로 제한할 수 있다는 것에 이점이 있습니다. 일반적인 뉴럴 네트워크와 다르게 ConvNet의 층들은 3차원의 뉴런으로 구성 되어있습니다(width, height, depth). 앞으로 다루겠지만, fully connceted 방법과 다르게 CNN에서 한 층의 뉴런들은 이전 층의 작은 영역에만 국한적으로 연결됩니다. 또한, CIFAR-10의 최종 출력층은 1X1X10 차원입니다. ConvNet 아키텍처의 구조로 우리는 이미지(full image)를 class 점수로 이루어진 단일 벡터로 축소할 수 있습니다.

2. 합성곱신경망에 필요한 층(Layers used to build ConvNets)
- 합성곱신경망(CNN) 아키텍처에서 사용하는 대표적인 층은 다음과 같습니다.
1) Convolutional Layer 2) Pooling Layer 3) ReLU 4) Fully-Connected Layer(일반적인 뉴럴네트워크와 같음)
- 아래는 위의 층으로 이루어진 가장 간단한 합성곱신경망(CNN)의 구조입니다.


이제부터 층이 어떤 기능을 하고 어떻게 구성되어있는지 자세하게 살펴보도록 하겠습니다.
2.1 Convutional Layer
(1) Conv layer에서의 connectivity
- Conv layer의 파라미터는 학습가능한 필터(learnable fileters)로 구성되어있으며, filter의 전형적인 사이즈는 5x5x3(width와 height는 5, depth(=color channel)은 3)입니다.
- feed forward 동안 filter를 입력 이미지를 슬라이딩하면서 내적하여 2차원의 activation map 생성하는데, 이 activation map은 모든 위치 공간에서의 해당 filter에 대한 반응 값이라고 할 수있습니다.
- 뉴런이 이전 층의 모든 값(volume)과 연결되는 대신, 일부 지역(local region)에만 연결합니다. 이때 연결되는 공간적 범위를 receptive field 라고 합니다(filter size와 동일).

(2) output volume의 크기를 정하는 hyper parameters
| depth (=filter count) |
- 사용하는 filter의 갯수와 같으며, 각각 입력값에서 다른 것(edge, blobs등)을 학습 |
| stride | - filter가 이미지를 슬라이드 할 때 이동하는 단위 (예: 1이면 한 칸(pixel)씩 이동) - stride가 클수록 output volume이 작아진다. - 보통 1을 사용한다. |
| zero-padding | - input volume을 0으로 감싸는 두께 - input volume과 output volume이 같도록 유지하는 역할을 한다. |
| filter size | - filter의 크기로, 보통 3x3과 1x1을 사용한다. |
위의 세개의 하이퍼파라미터가 output volume의 size를 정하는 식은 다음과 같습니다.

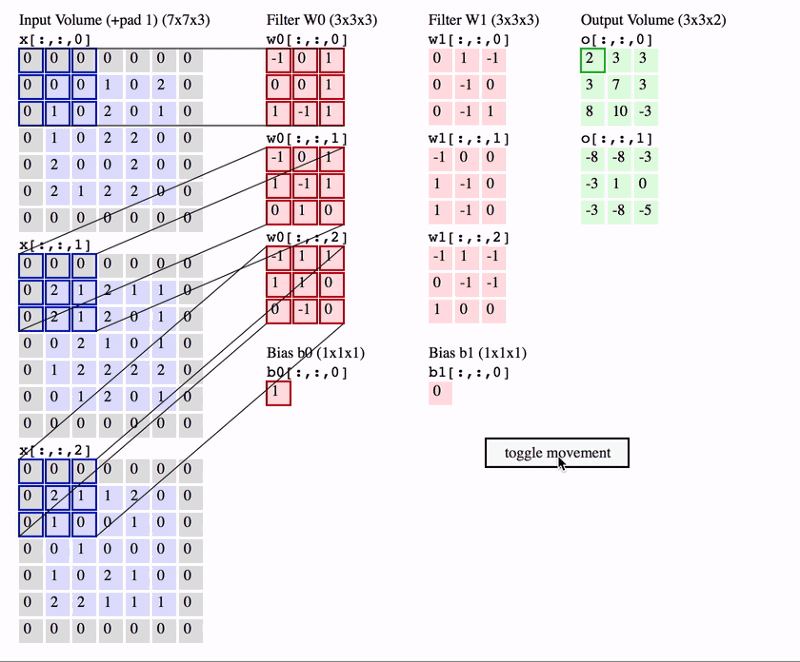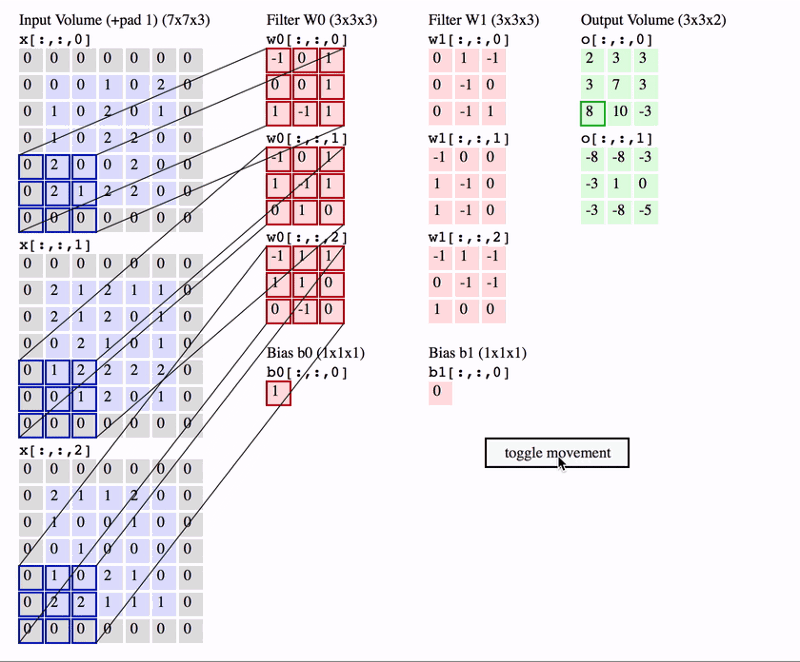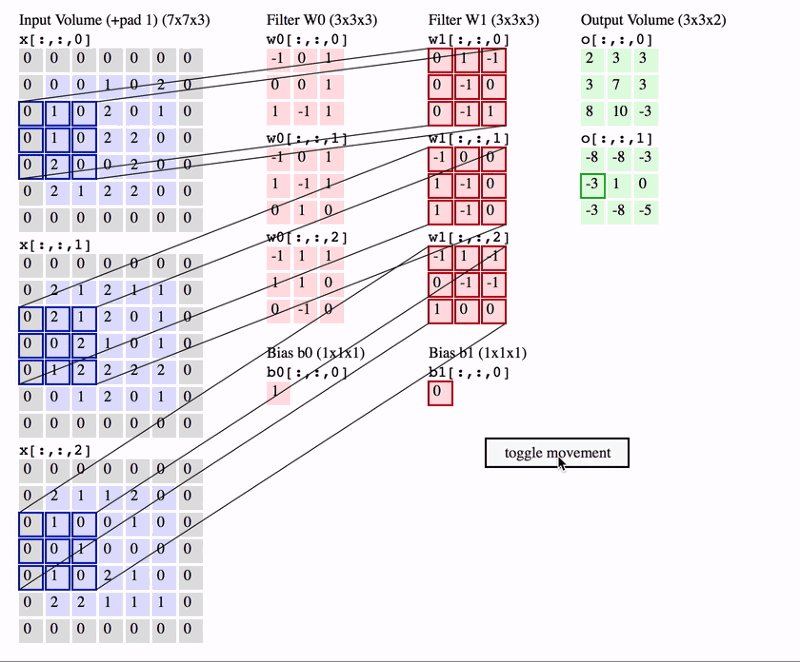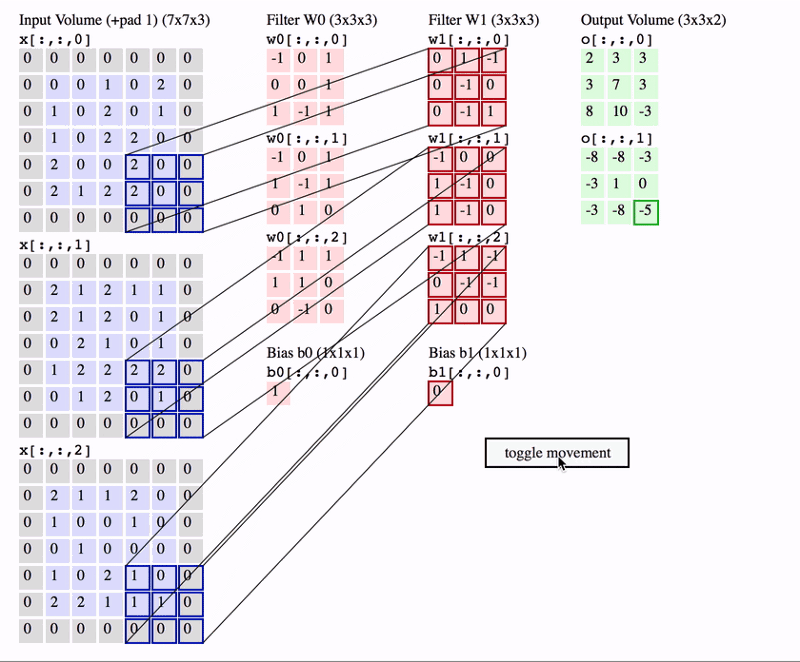
빠른 이해를 위해 간단한 예제를 살펴보자면,
input volume이 7x7, stirde가 1, zero padding은 0, filter_size 는 3x3인 Conv layer의 output volume은 얼마일까?
-> 답은 5x5 입니다. (아래 이미지에 풀이과정)


(3) 최근 CNN 하이퍼파라미터 트렌드
- 작은 filter sizes : 3x3 또는 더 작음
- 작은 pooling sizes : 2x2 또는 더 작음
- 작은 strides : 1
- '3x1x1' 법칙 : input volume이 나올 수 있도록 filter size를 3, stride를 1, zero padding을 1로 설정하는 것
'Parameter Sharing 개념'(2) Parameter Sharing
: Parameter Sharing은 특정한 공간 위치(x,y)에서 유용한 feature라면 다른 위치(x2,y2)에서도 유용할 것이라는 가정에서 나온 개념으로, Conv Layer의 한 depth(=fiter)에서 같은 가중치(weights)와 편향(bias)을 갖는다고 가정합니다.
'Parameter Sharing이 언제나 좋은 것은 아니다'
: Parameter Sharing은 specific centered structure의 경우 적합하지 않는데, 예를들면 위치별로 완전히 다른 feature가 학습되어야할 필요가 있는 경우를 생각할 수 있습니다. 얼굴사진의 경우, 위치에 따라서 눈 또는 머리에 특성화된 feature가 학습되어야 하죠. 이런 경우, parameter sharing을 완화하는데 이러한 층을 'Locally-Connected Layer'라고 부릅니다.
(3) Conv Layer 요약

2.2 Pooling Layer
(1) Pooling Layer의 역할
- Pooling Layer의 기능은 파라미터의 수와 그에 따른 네트워크에서의 연산비용을 줄이고 그 결과 오버피팅을 제어하기위하여 표현 공간 사이즈(spatial size of representation)를 줄이는 역할을 합니다.
- Poolying Layer은 MAX 연산을 사용하여 입력값의 모든 depth에서 독립적으로 작용한다.
- 가장 일반적으로는 아래 그림처럼 2x2 filter를 2 stride에서 적용합니다.

(2) Pooling Layer 요약

- Pooling Layer에서는 zero padding을 사용하지 않는 것이 일반적입니다.
- Pooling Layer의 spatial extent(F), stride(S) 세팅에는 두가지 대표 유형이 있습니다.
| Overlapping Pooling | Most Common |
| F=3, S=2 | F=2, S=2 |
- Max 연산 외에 평균 연산을 하는 'Average Pooling'과 'L2-norm Pooling'이 있습니다. Average Pooling은 전통적인 방법이지만, 실제 사례에서 더 성능이 좋은 Max Pooling이 등장한 이후로는 많이 쓰이지 않고 있습니다.
- 고층에서는 좋은 정보들이 추출되어있기 때문에 고층에서는 Average Pooling을 주로 저층에서는 Max Pooling 을 선호합니다.
(3) Pooling Layer가 항상 선호되지는 않는다.
- 오히려 Pooling Layer을 없애기 위한 연구도 진행되고 있습니다(Striving for Simplicity: The All Convolutional Ne).
- 특히, Pooling layer는 VAEs(variational autoencoders)이나 GANs(generative adversarial networs)와 같은 생성 모델(generative model)들을 학습 할 때에는 유익하지 않기 때문에, 미래의 아키텍처는 아마도 풀링 레이어가 거의 없거나 전혀 없을 것으로 예상하기도 합니다.
2.3 Fully Connected Layer
(1) Conv Layer과의 차이점
- FC(Fully Conncted Layer)와 CONV(Conv Layer)는 하나의 차이점만 빼고 동일한데, 그 차이점은 CONV layer이 입력값의 국부지역(local region)에만 연결되어 있다는것과 CONV의 많은 뉴런들이 파라미터를 공유(share parameter)한다는 것입니다.
- 그것을 제외하고는 두 layer 모두 내적(dot product) 연산을 하기 때문에 사실상 기능적인 형식은 동일합니다. 그래서 FC와 CONV 두 layer간 변환이 가능하죠.
| [CONV -> FC] - 모든 CONV layer은 같은 forward function 기능을 하는 FC layer 이 존재한다. - 해당 FC layer의 가중치 행렬(weight matrix)은 특정한 블록을 제외하고는(local connectivity) 대부분 0의 값을 가지며, 많은 블록의 가중치가 동일한 값을 가진다(parameter sharing). [FC -> CONV] - 역으로 모든 FC layer은 CONV layer로 변환할 수 있다. |
3. ConvNet 아키텍처
- 여러 Conv layer을 쌓는것이 더 유리하다
: 3개의 3x3 CONV layer을 연속적으로 쌓는다고 생각해보면, 두번째 CONV layer은 첫번째 CONV layer의 3x3을 보는것이고 그 말은 입력값(input volume)의 5x5를 보는것과 같습니다. 같은 방식으로 세번째 CONV layer는 두번째 CONV layer의 3x3을 보는것과 같고, 입력값(input volume)의 7x7 를 보는것과 같습니다. 결국 3개의 3x3 CONV layer을 쌓는것과 7x7 CONV layer 1개를 쌓는 것이 같다면 왜 굳이 3개를 쌓아야할까요? 그 이유는 아래와 같습니다.
<CONV layer 여러층이 유익한 이유>
1) CONV layer여러 개를 쌓으면 1개를 쌓을 때보다 비선형성을 포함하여 더 특성을 잘 표현할 수 있다.
2) 단일층(single layer)의 경우 더 많은 파라미터가 필요하다
: C개의 채널이 있다고 했을 때, 7x7 CONV layer 단일층은 Cx(7x7xC) = 49C²개의 파라미터가 필요하지만,
3X3 CONV layer 3층은 3x(Cx(3x3xC)) = 27C² 개의 파라미터가 필요합니다.
--> [결론] 더 적은 수의 파라미터로 더 강력한 특성(feature)를 학습할 수 있다.
4. CNN의 장점과 단점
<장점>
1. locally connectivity와 parameter sharing을 통해 고차원의 데이터를 오버피팅 되지 않고 다룰 수 있다.
- 'locally connevtivity': 이전 층의 모든 값이 아닌 지역적(local region)으로 연결하여 일부만 보고 하나의 feature 추출
- 'parameter sharing' : weight sharing이라고도 하며, 동일한 weight로 위치만 한칸씩 움직이면 되기 때문
2. 위치마다 동일한 feature를 추출하기 때문에 translation invariant 문제를 해결할 수 있다.
- 'translation invariant' : 이미지의 위치가 바뀌어도 이미지의 해석은 변하지 않는다는 개념
: '사과의 위치가 변해도 사과로 인식할 수 있어야한다'
3. local relationship을 추출할 수 있다.
<단점>
1. 연산량이 많다
- parameter 수는 적지만, filter를 하나씩 옮겨가며 촘촘히 계산하기 때문
: 모델 고속화 문제
2. 전체 데이터를 보고 특성을 추출할 수 없다
- 비유하자면, 코끼리의 귀만 보고 특성을 추출하는 상황
3. 여러 Pooling층을 거치면서 작은 local 정보를 잃을 수 있다.
<그 외>
- CNN의 핵심 개념들을 시각화와 함께 깔끔명료하게 정리한 글
CNN, Convolutional Neural Network 요약
Convolutional Neural Network, CNN을 정리합니다.
taewan.kim
'AI > 딥러닝 기초(Deep learning)' 카테고리의 다른 글
| [딥러닝][기초] 과적합(Overfitting)과 규제(Regularization) (0) | 2021.04.25 |
|---|---|
| [딥러닝][기초] Loss Curve, Accuracy Curve (2) | 2021.04.25 |
| [딥러닝][기초] 역전파 알고리즘(Back Propagation) 3_단점 (0) | 2021.04.25 |
| [딥러닝기초] 역전파 알고리즘(Back Propagation)_2 Delta Rule 일반화 (0) | 2021.04.25 |
| [딥러닝기초] 역전파 알고리즘(Back Propagation)1_ Delta Rule (3) | 2021.04.16 |



댓글