[Pytorch][BERT] 버트 소스코드 이해 목차 |
||||
| BERT | 📑 BERT Config | |||
| 📑 BERT Tokenizer | ||||
| 📑 BERT Model | 📑 BERT Input | |||
| 📑 BERT Output | ||||
| 📑 BERT Embedding | ||||
| 📑 BERT Pooler | ||||
| 📑 BERT Enocder | 📑 BERT Layer 👀 | 📑 BERT SelfAttention | ||
| 📑 BERT SelfOtput | ||||

BertLayer
1. BertLayer의 init()
✔ transformers.apply_chunking_to_forward
: 연산 효율화를 위해 chunk를 나누어서 계산한다.
: This function chunks the input_tensors into smaller input tensor parts of size chunk_size over the dimension chunk_dim.
It then applies a layer forward_fn to each chunk independently to save memory.
If the forward_fn is independent across the chunk_dim this function will yield the same result as not applying it.
2. BertAttention
◾ __init__()
◾ forward()
: BertselfAttention의 output과 거의 같지만,
Residual connection 과 Layer normalization 이 추가되었다는 것만 다르다!
2.1 BertSelfAttention
2022.10.28 - [자연어처리(NLP)] - [Pytorch][BERT] 버트 소스코드 이해_⑪ BertSelfAttention
[Pytorch][BERT] 버트 소스코드 이해_⑪ BertSelfAttention
BertSelfAttention 1. Attetion Process 1) key, query, value 생성 : 전체 hiddens_size를 실제로 attention 연산을 적용할 크기로 축소한다 2) attention score 구한다 3) context vector 구한다 (=output)..
hyen4110.tistory.com
2.2 BertSelfOutput
2022.10.28 - [자연어처리(NLP)] - [Pytorch][BERT] 버트 소스코드 이해_⑫ BertSelfOutput
[Pytorch][BERT] 버트 소스코드 이해_⑫ BertSelfOutput
BertSelfOutput
hyen4110.tistory.com
3. BertIntermediate
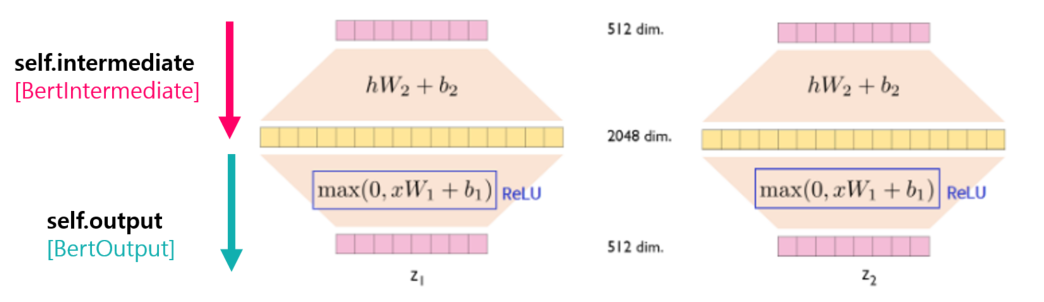
class BertIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
✔ intermediate_size
: (int, optional, defaults to 3072)
: Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
✔ hidden_act
: (str or Callable, optional, defaults to "gelu")
: The non-linear activation function (function or string) in the encoder and pooler.
: If string, "gelu", "relu", "silu" and "gelu_new" are supported.
4. BertOutput

'AI > 딥러닝 기초(Deep learning)' 카테고리의 다른 글
| [Pytorch][BERT] 버트 소스코드 이해_⑫ BertSelfOutput (0) | 2022.10.28 |
|---|---|
| [Pytorch][BERT] 버트 소스코드 이해_⑪ BertSelfAttention (0) | 2022.10.28 |
| [Pytorch][BERT] 버트 소스코드 이해_⑨ BERT model 출력값 (0) | 2022.10.28 |
| [Pytorch][BERT] 버트 소스코드 이해_⑧ BERT model 입력값 (0) | 2022.10.28 |
| [Pytorch][BERT] 버트 소스코드 이해_⑦ Bert Pooler (0) | 2022.10.28 |




댓글