1. 딥러닝 모델에서는 과적합(Overfitting)이 필요하다
- 딥러닝 모델은 일반적으로 최대한 오버피팅을 시킨 후 규제 등을 통해 오버피팅을 해결해나갑니다. 근데 왜 꼭 그렇게 해야만할까요? 처음부터 오버피팅이 안되도록 아키텍처를 설계하면 안될까요?
- 딥러닝(deep learning)은 'representation learning'(또는 'feature learning')의 하위 분야입니다. 기존의 통계 모델에서는 이미 알려진 사실을 바탕으로 사람이 직접 feature를 추출하고 가공하는 feature engineering 과정이 필요했지만, 딥러닝 모델에서는 raw data에서 모델이 직접 feature를 만들어 냅니다.
- 그렇기 때문에 처음부터 아키텍처를 simple 하게 설계한다면, high level의 feature를 학습할 수 없습니다. 꼭 복잡한 아키텍처가 좋은 것은 아니지만, 아키텍처를 크게해서 오버피팅이 되도록 하고 그 후에 규제 등을 가하여서 오버피팅을 해소해 나가는 방법이 선호됩니다.

2. 과적합(Overfitting)을 해결하는 방법
2.1 데이터 수집
- parameter의 수가 data의 수보다 많은 경우, 모델은 학습과정에서 train data의 pattern을 외울 수 있고 이로 인하여 과적합, 오버피팅이 발생하게 됩니다.
- 사실 오버피팅을 방지하는 많은 방법들이 있지만, 그 중 가장 좋은 방법은 데이터를 더 수집하는 것입니다
2.2 데이터 확장(Augmentation)
- 데이터를 수집하면 좋겠지만, 수집은 사실상 비용의 문제로 어려운 경우가 많습니다.
- 이런 경우, 이미 확보한 데이터를 변형하는 등의 방법으로 생성할 수 있습니다.
- 샘플의 분포 양상을 예상할 수 있는 경우에 유효하며, 예를 들어 이미지의 경우 평행이동, 거울상반전, 회전(rotate), 명암값이나 색에 변동을 가하거나 점잡음 (Salt and pepper noise) 등의 노이즈를 추가할 수 있습니다.
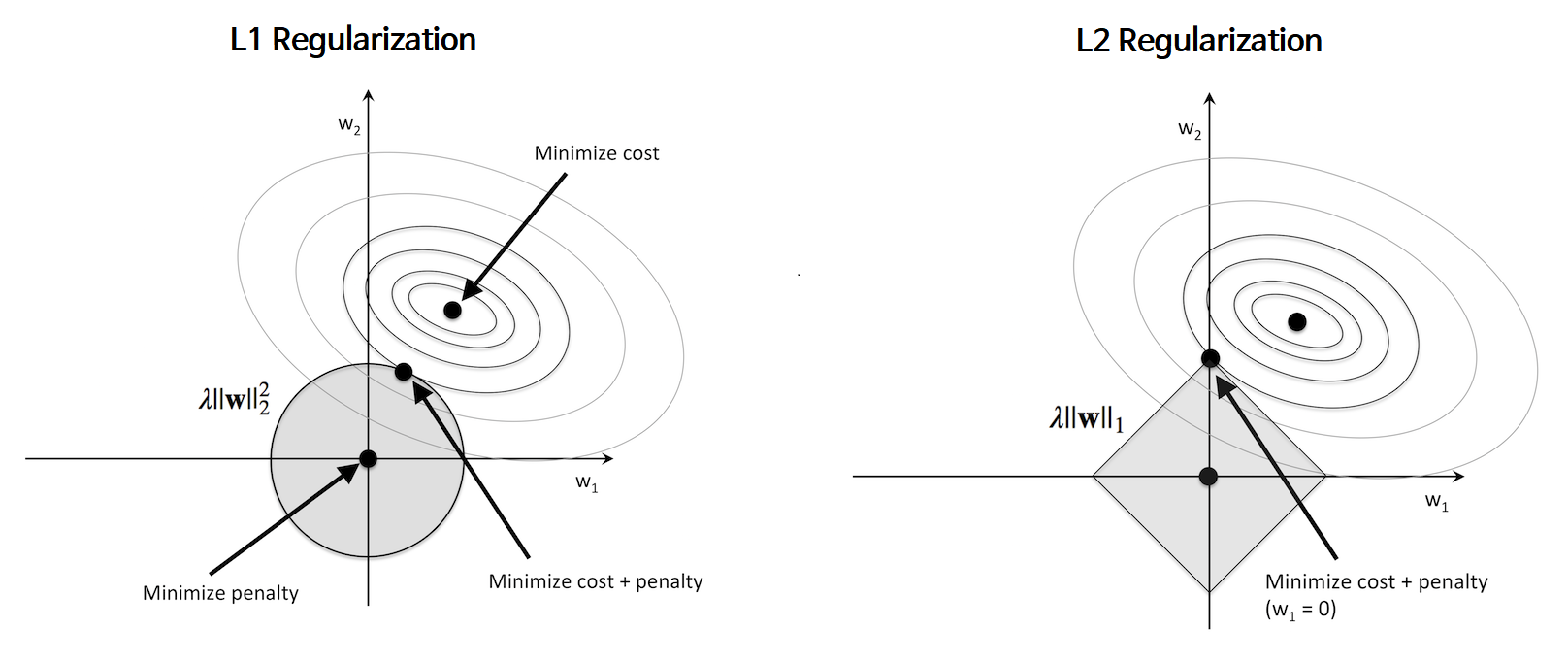
2.3 가중치 규제(Weight Regularizaition)
- 경사하강법에서는 Error Function이 감소하는 방향으로 가중치를 업데이트 합니다.
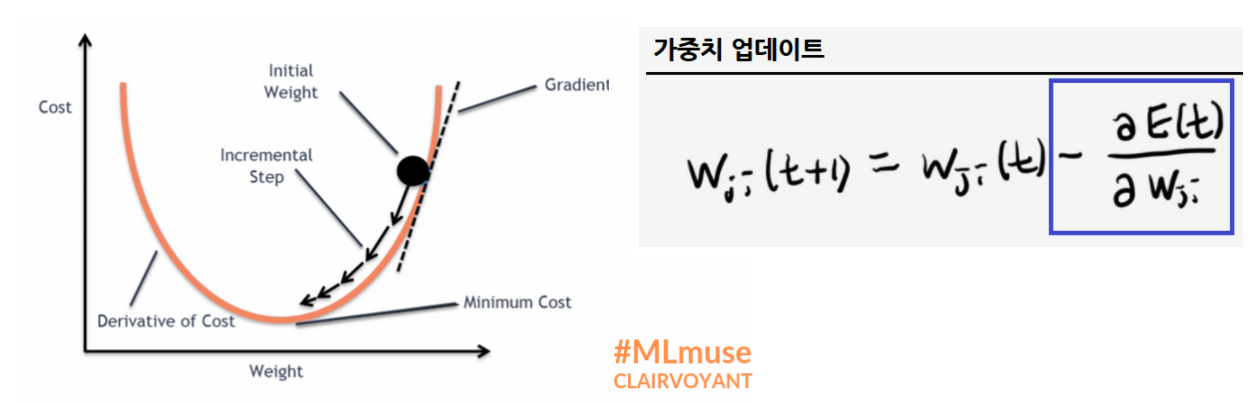
- 이때 Error Function에 가중치의 크기를 표현한 항(이미지에서는 L2 norm)을 추가하여,
기존의 Error를 최소화 할 뿐만 아니라 가중치도 같이 최소화하도록 규제를 추가합니다.
- λ는 규제의 강도를 제어하는 파라미터로, 0.01~ 0.00001 정도의 값을 사용

이와같이 Error Function에 가중치를 추가하는 방법중 대표적인 3가지를 소개하겠습니다.
( 규제는 한가지 방법만 쓰지 않고, 동시에 여러가지 방법을 함께 사용합니다.)
| 규제 | regularization 항 | 설명 |
| L2 regularization (가중치 감쇠) |
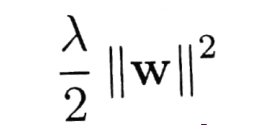 |
- 'Weight decay(가중치 감쇠)' 라고도 한다. : regularization항을 미분하면 λw이 되는데, 이것이 가중치 업데이트양(-)에 추가되어, 결국 자기자신의 크기에 비례하는 속도로 감소하기 때문에 weight decay("decay": 썩는다) 라고 합니다. 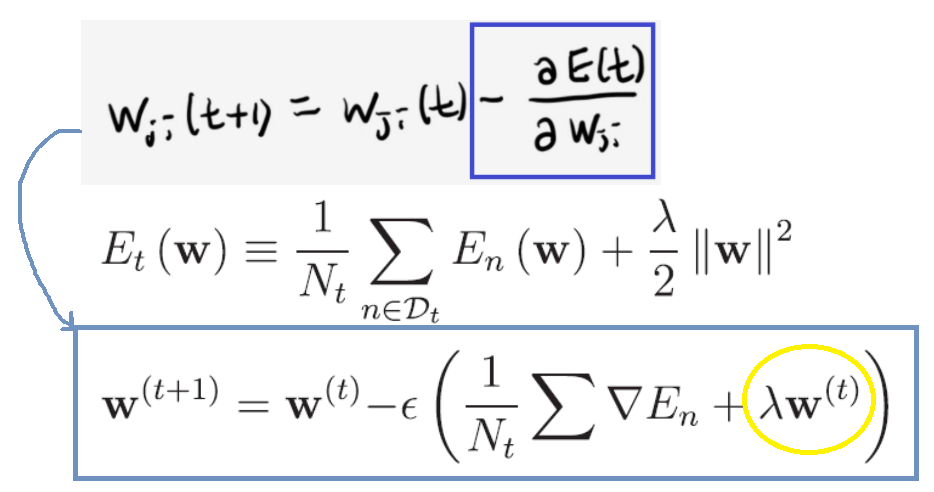 - L2 regularization은 수식적인 해를 구할수 있다는 장점이 있고, 제곱을 최소화하기 때문에, w값이 완전히 0이 되는 경우가 L1보다 적음 |
| L1 regularization |
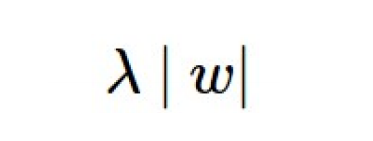 |
- 'Sparsity inducing norm' 이라고도 한다. : *각각의 크기를 최소화하여 대부분의 가중치가 0이 되도록하여 sparse하게 만들기 때문! (아래 그래프 그림을 보면 이해가 더 쉽습니다!) - 가중치가0이 되는 특성은 오차를 줄이는데 영향이 없다고 판단하여, 결과적으로 특성 선택(feature selection) 성질이 있다고 할 수 있습니다. |
| Max norm constraint (가중치 상한) |
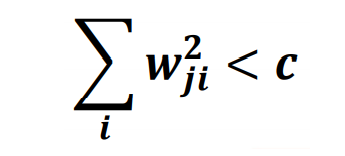 |
- 각 유닛의 입력층 결합의 가중치에 대해서 그 제곱합의 최댓값을 제약하는 방법 - 조건이 만족하지 않을 경우, 상수(1보다 작은)를 곱하여 부등식을 만족하도록 함 |
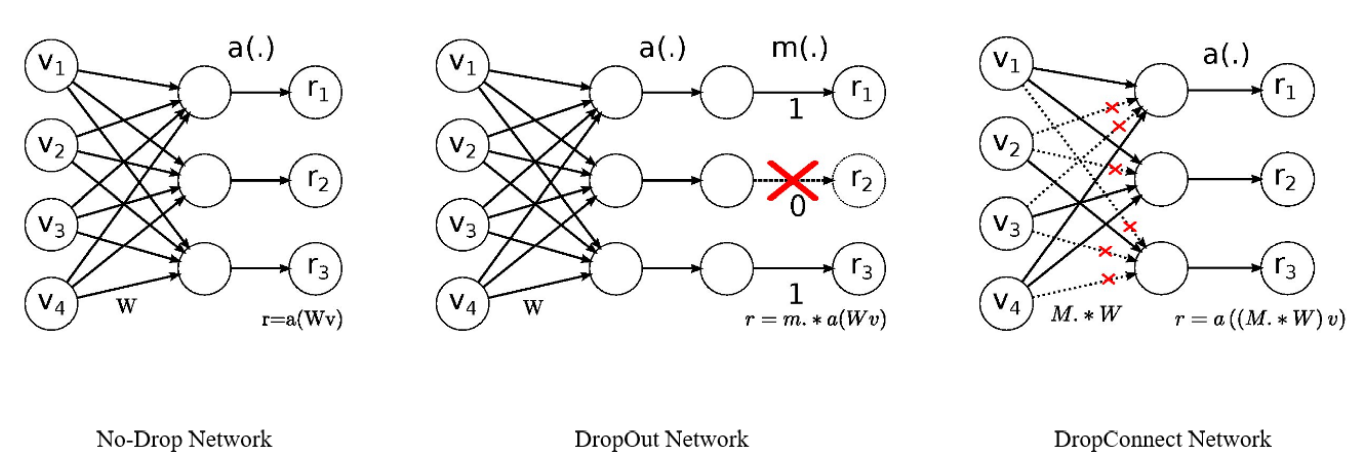
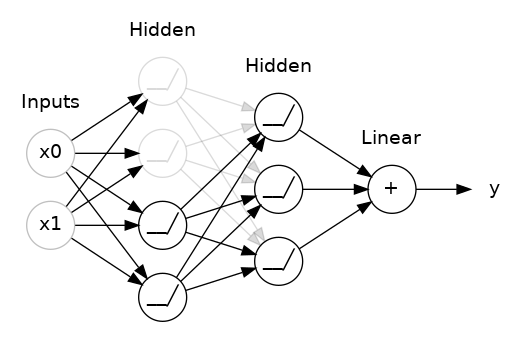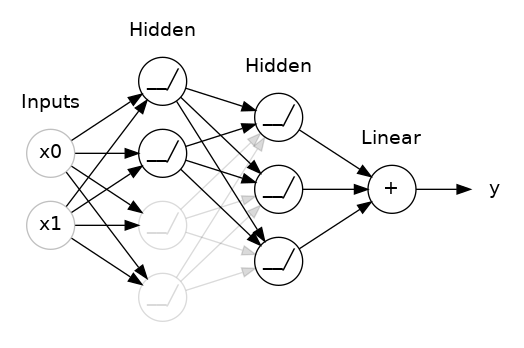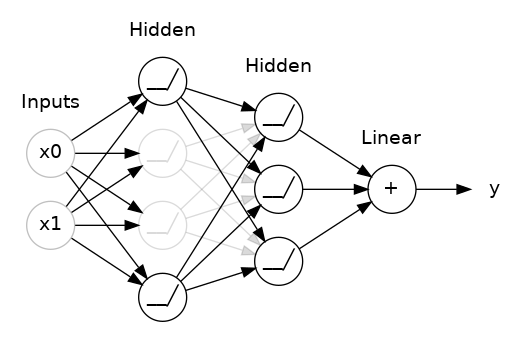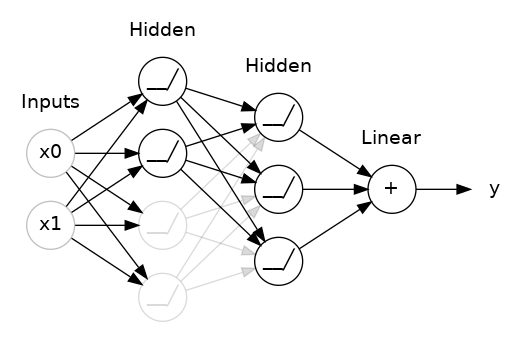
2.4 드롭아웃(Dropout), 드롭커넥트(Dropconnect)
| 규제 방법 | 이미지 | 설명 |
| 드롭아웃 (Dropout) |
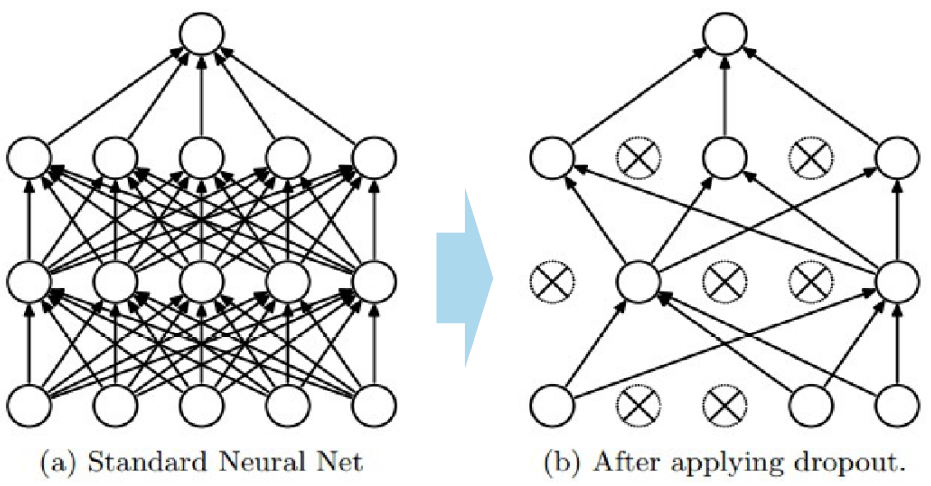 |
"다층신경망의 유닛 중 일부를 선택하여 학습" - [방법] : 다층p의 확률로 뉴런을 임의적(randomly) 없앤다(원래 존재하지 않았던것처럼 취급) : test 데이터에서는 dropout을 하지 않는다. -> 이를 보상하기 위해 p를 곱해준다. 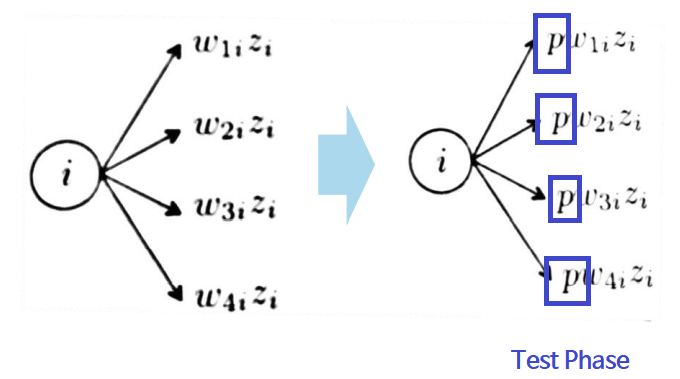 : 매 iteration 마다 다른 유닛을 선택하며 p도 변화를 준다. : 보통의 경우 출력층과 가까운 layer에 dropout을 넣지만 케이스마다 다르다. - [효과] 매 iteration 마다 다른 dropout으로 인한, 다른 아키텍처를 학습하기 때문에 training 데이터에만 있는 pattern을 외우기 힘들다 - [단점] 학습이 좀 더 오래 걸리고, accuracy curve에 진동(oscilaltion)이 생긴다 |
| 드롭커넥트 (Dropconnect) |
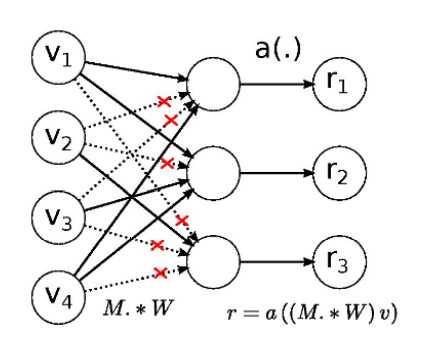 |
"다층신경망의 가중치 중 일부를 선택하여 학습" |
'AI > 딥러닝 기초(Deep learning)' 카테고리의 다른 글
| [딥러닝][기초] 딥러닝 학습을 위한 Trick들 (0) | 2021.04.29 |
|---|---|
| [딥러닝][기초] 활성화 함수(Activation Function) (0) | 2021.04.25 |
| [딥러닝][기초] Loss Curve, Accuracy Curve (2) | 2021.04.25 |
| [딥러닝][기초] 역전파 알고리즘(Back Propagation) 3_단점 (0) | 2021.04.25 |
| [딥러닝기초] 역전파 알고리즘(Back Propagation)_2 Delta Rule 일반화 (0) | 2021.04.25 |


댓글