이 글은 아래 유뷰트 강의, 사이트 내용, udemy 강의 'Deep Learning: Advanced NLP and RNNs' 을 정리한 글입니다.
www.youtube.com/watch?v=bBBYPuVUnug
d2l.ai/chapter_recurrent-modern/seq2seq.html
www.udemy.com/course/deep-learning-advanced-nlp/
Deep Learning: Advanced NLP and RNNs
Natural Language Processing with Sequence-to-sequence (seq2seq), Attention, CNNs, RNNs, and Memory Networks!
www.udemy.com
(이후 수식 파트는 김기현 강사님의 딥러닝을 활용한 자연어생성 강의를 수강하고 정리하였습니다)
1. Sequence to Sequence 의 등장 배경
- 등장배경 설명을 위해 한 언어의 문장을 다른 언어의 문장으로 변환하는 기계번역을 예시로 설명하겠습니다. 가령, 영어를 프랑스어로 번역한다고 했을 때 발생하는 문제점이 있습니다. 일반적인 번역에서 영어 문장과 번역한 후의 프랑스어 문장은 서로 단어수가 정확히 일치하지 않는다는 것입니다. 또한, 영어 문장에서의 단어의 순서와 프랑스 문장에서의 순서도 같지 않습니다(예: 영어에서는 주어 다음에 동사가 나온뒤 목적어가 나오지만, 한글의 경우 주어 다음에 목적어가 먼저 나온 후 동사가 나오듯이 말입니다.)
[English] the black cat drank milk (5 words)
[French] le chat noir a bu du lait (7 words)
- 하지만 기존의 RNN 모델은 하나의 입력값에는 하나의 은닉층(hidden state)과 하나의 출력값이 존재했기 때문에, 출력값의 길이는 입력값의 길이와 늘 동일할 수밖에 없습니다. 영어 문장에서 존재하는 수와 번역 후 프랑스어 문장에 존재하는 단어수가 같아야하는 말도 안되는 제약이 존재하게된 것입니다. 이러한 한계점을 해결하기 위하여 'Sequence to Sequence' 모델이 제안되었습니다.
2. Sequence to Sequence 기본 구조
- 기본 아키텍처는 2중 RNN으로 이루어져있습니다. 이 중 처음 번역할 문장을 입력값을 받는 RNN을 Encoder라고 하고, 뒤에서 번역된 문장을 생성하는 RNN을 Decoder라고 합니다.

2.1 Encoder
1) Encoder가 하는 일 - 입력 문장을 하나의 벡터로 만들기
: Encoder는 입력 시퀀스(문장)를 정해진 크기의 context vector(c)로 변환하여 Decoder에게 넘겨줍니다.
: 이 context vector(c)에 입력 시퀀스(x1, x2....xT)의 정보를 담습니다(인코딩).
-> Encoder는 문장을 받아서 하나의 숫자벡터로 표현하며, Decoder는 숫자벡터를 받아서 문장으로 표현합니다.
2) Encoder의 특징 - 입력 문장을 통째로 처리/Non-Autoregressvie
: Encoder는 각 time-step의 출력값이 이전 time-step의 영향을 받는 auto-regressive task가 아닌
Non-auto-regressive task에 해당하기 때문에 Bidirectional RNN을 사용할 수 있습니다.


- Encoder unit은 LSTM, GRU와 같은 모델이지만, 예측을 하지 않기 때문에 각 time step별 출력값을 두지 않습니다. 이 RNN 모델에서의 유일한 출력값은 마지막 은닉상태인 h(T) 이며, 만일 모델이 LSTM이라면 h(T)와 c(T)가 될 것입니다.
- h(T) 값은 시간 정보를 가지고 있지 않으며, 오로지 입력값에 대한 표현 정보만을 가지고 있습니다. 그래서 이것을 'encoding'이라고 부르며 원래의 입력값에 대한 요약된 표현이 되겠습니다.
- time step t에서의 은닉상태 h(t)는 입력값 x(t)와 이전 은닉상태의 함수가 됩니다.
3) Encoder를 수식으로 이해하기
<1> 입력 출력 시퀀스의 수식 및 사이즈(텐서)
i) 데이터셋(D)는 입력 시퀀스(x)와 출력 시퀀스(y)의 쌍(pair)로 이루어짐
ii) x는 단어의 수(길이)가 m개/ y는 단어의 수(길이) 가 n+1
-> 출력시퀀스의 처음과 마지막은 각각 <BOS>와 <EOS>
iii) 각 시퀀스는 이후 코드에서 텐서로 표현
-> 입력 시퀀스의 텐서크기: (bs, m, |Vs|) / 출력시퀀스의 텐서크기: (bs, n, |Vt|

<2> 은닉층 크기
i) 현재 시점의 입력 단어(Xt)는 인코더의 Embedding Layer를 먼저 지나간다
-> 텐서의 크기가 (bs, 1, |Vs|) 에서 (bs, 1, ws)로 바뀜
ii) 인코더의 RNN에서 이전 time-step(t-1)의 은닉층(hidden-state)과, 현재 입력 단어의 워드 임베딩을 통해
현재 시점(t)의 은닉상태(hidden-state)를 구한다.
-> time-step(t)에서의 은닉상태(hidden-state) 텐서의 크기 = (bs, 1, hs)

2.2 Decoder
1) Decoder가 하는 일 - Encoder가 압축한 숫자벡터를 받아서 문장 생성
: Encoder가 출력한 숫자 벡터(context vector)와 현재까지 출력한 단어들을 바탕으로 다음 단어를 예측
2) Decoder의 특징
- Decoder는 출력 시퀀스의 특정 time-step이전의 단어들을 가지고 현재 time-step을 예측하기 때문에 Conditional language model이라고 할 수 있습니다.

- Encoder와 다르게 auto-regressive task에 속하기 때문에, Bidirectional RNN은 쓸수 없으며 Uni-directional RNN을 사용할 수 밖에 없습니다.
- Decoder는 Encoder RNN과는 다른 고유의 가중치를 가진 RNN unit 입니다.
- Encoder의 마지막 은닉상태(hidden-state)를 Decoder의 처음 은닉상태(hidden-state)로 넣습니다.

- Decoder의 time step t'에서의 출력값(y('t'))의 확률은 context 벡터 c와 이전 출력 시퀀스(y(1),...,y(T))에 따라서 달라집니다.
- Decoder는 Encoder와 별개의 unit이지만 크기는 같아야하는데 그 이유는 Encoder의 유일한 출력값인 은닉상태(h(T))를 입력값으로 받아야하기 때문입니다. 즉 Encoder의 출력값인 마지막 step의 h(T)는 Decoder의 첫 입력 은닉상태인 s(0)이 됩니다.
- Decoder에서는 첫 입력값으로 문장의 시작을 알리는 입력값인 '<start-of-sentence>/<sos>' 벡터를 지정합니다.
- 은닉상태 s(t)는 이전 출력값인 y(t'-1)과 convex vector c와 이전 은닉상태 s(t'-1)의 함수입니다.
(즉 Decoder의 time step t에서의 입력값 x(t')는 y(t'-1)과 같다고 보면 되겠습니다)
- 정확하게 이야기하면, Decoder는 단어를 단순히 생성하는것이 아니라, 출력될 수 있는 여러 단어들의 확률을 예측합니다. 즉 벡터에 softmax 함수를 써서 확률값으로 변환한 후, 가장 나올 확률이 높은 단어 1개를 출력합니다. 이를 최적화를 위해서 cross-entropy loss함수를 사용합니다.
3) 수식으로 이해하는 Decoder
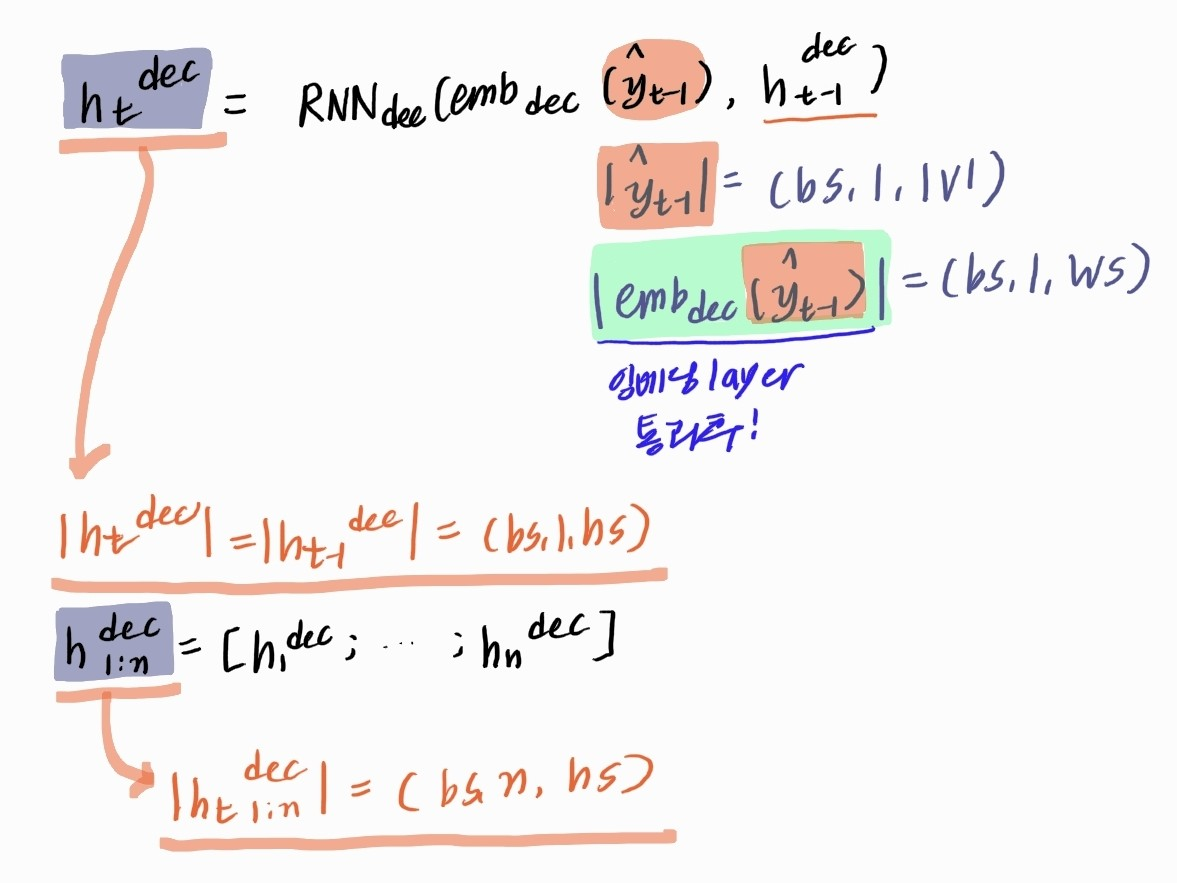

3.2 Generator
1) Generator가 하는 일 - Decoder의 은닉상태(hidden-state)로 현재 time-step의 출력 단어 분포 예측
: Decoder의 현재 time-step의 은닉상태(hidden-state)를 받아서 각 단어별 확률(분포)를 예측합니다.
-> Cross Entropy Loss로 최적화함
: 은닉상태(hidden-state)과 vocabulary_size는 다르기 때문에, 크기가 (hs, |V|)인 W(gen) 벡터를 곱해줍니다.

3. Seq2Seq 의 활용
앞에서는 기계번역만을 예로 들었습니다. 하지만, Seq2Seq 로 해결할 수 있는 작업은 그 외에도 많습니다. 대표적인 몇가지를 소개하도록 하겠습니다.
1) Question Answering (QA)
- 이야기(story)와 문제(question)가 주어졌을때, 답(answer)을 생성해내는 문제 입니다. 일종의 독해력 테스트(test of reading comphrehension)과 같은 것이죠.
- 알버트 아인슈타인에 대한 위키피디아 페이지가 주어졌을 때, "아인슈타인의 이론 중 가장 유명한것이 무엇입니까?"라고 질문한다면 뉴럴네트워크는 "Relativity"라고 대답해야할 것입니다.
- Seq2Seq 구조에서 문제를 본다면, 이야기와 문제가 합해져서 입력 시퀀스가 될 것이고, 이 입력 시퀀스는 인코더를 거쳐서 'thought vector(=context vector)'가 되고 이 thought vector는 디코더를 거치면서 답으로 디코딩 될 것입니다.
2) Chatbots(챗봇)
- 챗봇의 경우, 텍스트로 요청(request)을 하면 반응(response)을 하는 문제로, 기계번역과 동일하게 시퀀스를 입력해서 시퀀스를 받는 문제입니다.
- 챗봇 외에도 텍스트 요약(Text Summarization) 또는 STT(Speech to Text) 등이 있습니다.
다음 글에서는 Attention에 대하여 알아보도록 하겠습니다.
'AI > 딥러닝 기초(Deep learning)' 카테고리의 다른 글
| [NLP] Bahdanau Attention(바다나우 어텐션) (0) | 2021.05.16 |
|---|---|
| [NLP] Attention Mechanism(어텐션) (0) | 2021.05.12 |
| [딥러닝][NLP] Bidirectional RNN (0) | 2021.05.12 |
| [딥러닝] GRU(Gated Recurrent Unit) (1) | 2021.05.10 |
| [딥러닝][NLP] LSTM(Long Short Term Memory Networks) (1) | 2021.05.07 |




댓글