김기현 강사님의 '자연어처리 딥러닝 캠프(파이토치편)' 책을 공부하면서 정리한 글입니다.
김기현의 자연어 처리 딥러닝 캠프: 파이토치 편 - 교보문고
딥러닝 기반의 자연어 처리 기초부터 심화까지 | 저자의 현장 경험과 인사이트를 녹여낸 본격적인 활용 가이드 이 책은 저자가 현장에서 실제로 시스템을 구축하며 얻은 경험과 그로부터 얻은
www.kyobobook.co.kr
*수식으로 확인하는 Encoder
> 지난 글 : 2021.05.12 - [자연어처리(NLP)] - [NLP] Sequence to Seqence(Seq2Seq)

1. Encoder 클래스
- nn.Module을 상속 받음 (nn.Module은 파이토치에서 신경망과 관련된 모든 모듈의 기초 클래스)
Bidirectional LSTM
- nn.LSTM 클래스를 상속 받아 만든다
- hidden_size= int(hidden_size/2) (∵Bidirectional 이므로)
- batch_first =True (∵ batch_size를 첫 값으로 지정)
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequence as pack
from torch.nn.utils.rnn import pad_packed_sequence as unpack
import simple_nmt.data_loader as data_loader
from simple_nmt.search import SingleBeamSearchBoard
from torch import nn
class Encoder(nn.Module):
def __init__(self, word_vec_size, hidden_size, n_layers=4, dropout_p=.2):
super(Encoder, self).__init__()
self.rnn = nn.LSTM(
word_vec_size, # input shape
int(hidden_size / 2), # bidirectional
num_layers=n_layers, # stacking LSTM
dropout=dropout_p,
bidirectional=True,
batch_first=True
)
| torch.nn.LSTM(*args, **kwargs) |
[forward 함수]
- 임베딩된 텐서를 받아서 모든 time-step 통째로 진행
(∵ seq2seq의 Enocoder은 non-auto-regressive하기 때문)
- 입력 시퀀스를 0으로 패딩(pack = pack_padded_sequence), 및
def forward(self, emb):
# |emb| = (batch_size, length, word_vec_size)
if isinstance(emb, tuple): # emb가 튜플이라면,
x, lengths = emb
x = pack(x, lengths.tolist(), batch_first=True)
else:
x = emb
y, h = self.rnn(x)
# |y| = (batch_size, length, hidden_size(/2)(*2)-> 정방향+역방향)
# |h[0]| = (num_layers * 2, batch_size, hidden_size / 2)
if isinstance(emb, tuple):
y, _ = unpack(y, batch_first=True)
return y, h- 여기서 return 하는 y, h
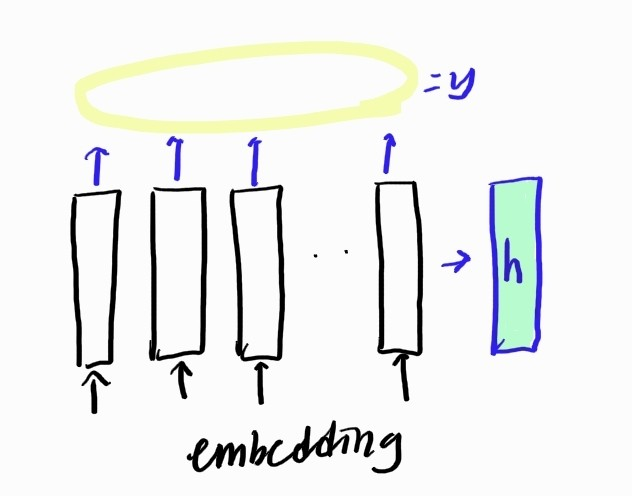
- y : 전체 time_step의 마지막 layer의 hidden_state
- h : 마지막 time_stpe의 hidden_state으로, 여기서는 LSTM이기 때문에 hidden_state와 cell_state의 튜플 구조로 이루어짐 --> (h(n), c(n))
| <pad_sequence> :torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False, enforce_sorted=True) : Tensor 리스트를 받아서 가장 긴 길이의 시퀀스를 기준으로 제로 패딩해주는 함수   |
| <pack_padded_sequence> torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False, enforce_sorted=True) : 제로 패딩한 시퀀스 리스트를 처리하기 쉽도록, 시퀀스의 길이가 긴 순서대로 정렬 ( forward이후 다시 반환할때에는 순서가 바뀌면 안되므로, 순서 변환을 기억하는 'unsorted_indices' 변수도 자동으로 생성됨)   |
'AI > 파이토치(Pytorch)' 카테고리의 다른 글
| [파이토치] 텐서 기초 (0) | 2021.09.08 |
|---|---|
| [딥러닝][파이토치] 이그나이트 이벤트(Ignite Events) (0) | 2021.09.03 |
| [딥러닝][파이토치] 이그나이트_엔진(Ignite_Engine) (0) | 2021.09.03 |
| [NLP][파이토치] seq2seq - Decoder(디코더) (0) | 2021.08.30 |
| [NLP][파이토치] seq2seq - Attention(어텐션) (0) | 2021.08.30 |



댓글