이번 글에서는 BERT의 원리에 대해서 깊게 살펴보고자 합니다.
이번 글을 작성하기위해서 참고한 글 리스트는 아래와 같습니다.
1) KoreaUniv DSBA 08-5: BERT https://www.youtube.com/watch?v=IwtexRHoWG0
2) http://jalammar.github.io/illustrated-bert/
1. BERT(Bidirectional Encoder Representations from Transformers)란?
1.1 등장 배경
- 트랜스포머의 등장으로 인한 기계번역 분야에서의 성과로 인해서, 트랜스포머는 다른 분야에서도 LSTM을 대체할 수 있는 후보로 대두되었습니다.
- 그러나 트랜스포머의 인코더-디코더 구조는 기계번역 task에는 아주 완벽하지만, 만약 문장 분류에 이 구조를 사용한다면 어떻게 해야 할까요? 아니면 다른 task를 위해 파인 튜닝된 언어모델을 사전학습하는데 사용하기 위해서는 어떻게 해야할까요?
1.2 BERT 소개
1) Transformer의 인코더만을 Bidirectional하게 사용하는 모델
: BERT를 요약하자면, Transformer의 인코더만을 Bidirectional하게 사용하는 모델이라고 할 수 있습니다. BERT의 구조는 주로 2가지의 목적을 가지고 언어모델을 학습을 합니다.
1) Masked Language Model : 순차적(forward 또는 backward)으로 단어정보를 사용하지 않고, 특정 위치의 부분을 마스킹하고 선행단어와 후행단어를 사용하여 특정 단어를 예측하도록 하는 모델
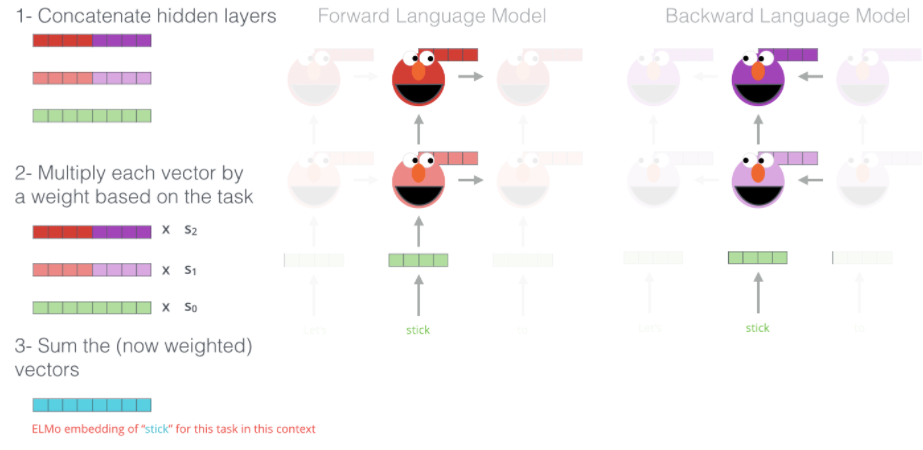
*ELMo: forward 와 backward를 따로 학습해서 결합
- GPT: 트랜스포머의 디코더부분의 단어들을 전부 마스킹하고 학습
2) Next Sentence Prediction : 두 문장이 주어졌을때, 한 문장이 다른 문장의 바로 다음에 오는 문장인지 아닌지 예측하는것
2) pretrained 된 네트워크
- 사전에 대용량 데이터를 학습하여 만든 모델로 나중에 원하는 task를 처리할 수 있도록 파인 튜닝 하는 것
| Pre-trained 모델을 만드는 방법 2가지 | |
| 1) Feature-based | - 파라미터가 고정됨 - 예) ELMo (Shallowrly Bidirectional LM(forward+backward) 사용) : 일반적으로 LSTM의 Top layer만으로 예측하지만, 아래의 layer도 추가시켜서 task에 학습 : top layer로 갈수록 더 큰 중요도 부여  |
| 2) Fine_tuning | - 파라미터가 고정되지 않음 - 예) GPT : BERT는 Bidirectional Language Modle인 반면, GPT는 Directional |
3) Transformer의 목적함수가 변형된 형태
- Transformer는 이전 단어들을 보고 다음 단어를 예측(Uni-directional)하지만, BERT는 주변 단어들을 보고 Masked된 단어를 예측(Bi-directional)하기 때문에 다른 목적함수를 사용합니다.
| 손실함수 | |
| 1) Masked 단어 예측 |  |
| 2) 다음 문장 여부 예측 |  |
2. 모델 아키텍처
2.1 BERT의 두가지 모델 (base, large)

1) BERT(base)
- L = 12, H = 768, A = 12
- 총 parameter수 : 110M(1억 1천만 개)
- Open AI GPT와 비교하기 위하여 같은 모델 사이즈(복잡도)를 설정
2) BERT(large)
- L = 24, H 1,024, A = 16
- 총 parameter 수 : 340M(3억 4천만 개)
| * BERT의 하이퍼파라미터들 | |
| L | 인코더 layer(=트랜스포머 블록)의 층 개수 |
| H | FFN(Feedforward-Network)에서 hidden size |
| A | self-attention head 수 |
2. Pre-training 과정
2.1 input representation
[입력 문장 나누기]
- 입력값으로는 한 문장 또는 Question 과 Answer과 같은 한 쌍의 두 문장을 입력값으로 넣을수 있다.
(※ 여기서 '문장'의 기준은 언어학적으로 완전한 문장이 아니어도 되며, 연속적인 단어의 나열이면 문장으로 본다)
- 입력의 첫번째 토큰은 [CLS]로 'Classification'을 의미하며 [SEP] 토큰은 한 문장의 종료를 알린다

- 입력 문장의 최대값은 하이퍼파라미터(max_sequence_length)로 제어하며, 여기에는 토큰([CLS],[SEP],[SEP])가 포함된다.
: 예를 들어 max_seqence_length = 16이면, 토큰 3개를 제외한 후 한후 남은 토큰 13개가 문장 내 단어로 이루어진 토큰이 될 수 있다.
 - 최종 입력시퀀스의 max가 16일때, 단어 토큰은 13개가 가능하므로, Document1에서는 문장 1,2,3까지만 가능하다 - 입력 시퀀스1과 입력시퀀스2를 어떻게 조합해서 넣느냐는 random하게 결정한다. : 예를들어 문장1,2=입력시퀀스1/문장3=입력시퀀스 2로 할지, 문장1=입력시퀀스1/문장2,3= 입력시퀀스 2로 할지는 random |
|
| 앞뒤 문장을 넣은 경우 |  |
| 다른 문서에서 가져와서 넣은 경우 |  - randomness와 bias를 주기위하여 가장 긴 토큰 리스트에 대해서 50%의 확률로 앞 또는 뒤의 토큰을 제거한다.  |
[출처] https://www.youtube.com/watch?v=xhY7m8QVKjo
[임베딩]
| 임베딩 종류 | 과정 |
| Input embedding |
 |
| Positional embedding |  |
| Segment embedding |  |

[마스킹]
1) 보통 문장의 15%를 마스킹처리하며, 입력 토큰 중에서 마스킹을 할 값의 위치는 index로 기록한다.

2) 마스킹하기로한 토큰 중 80%는 [MASK] 토큰으로 대체, 10% 는 임의의 단어(random 토큰)로 대체, 10%는 원래 토큰으로 둔다.

3) input representation 과정의 placeholder

[Transformer와 BERT의 차이점(input representation에서)]
| Transformer | BERT | |
| 토큰 유형 | [BOS] : 문장의 시작 [EOS] : 문장의 끝 |
[CLS] : task에 대한 정보 토큰 [SEP] : 문장1,2의 끝을 알려주는 토큰 [MASK] : 예측하는 target 토큰 |
| 임베딩 vector 종류 | 1) Input embedding 2) Positional embedding |
1) Input embedding 2) Positional embedding 3) Segment embedding : 문장 1,2에 대한 구분 정보  |
| Scaling & Dropout | LayerNorm & Dropout | |
| Query, Key 마스킹 | - Query(form), Key(to) Masking 둘다 사용 |
- Key(to) Masking(받는 마스킹)만 사용 |
| Multi-head attention 후 concat 여부 | - Multi-head attention을 concat 해 그대로 보냄 |
- Multi-head attention을 concat 후 Dense layer을 적용한 후 Dropout |
| 활성화함수 | ReLU 또는 1D conv | GeLU |
| ouptut 그대로 내보냅 | otuput Dropout |

2.2.1 출력값
- 각 단어의 위치별로 hidden_size의 벡터크기 만큼의 출력값을 가집니다(BERT base 모델: 768).
- 첫번째 토큰([CLS])의 처리를 예로들면, 토큰 [CLS]의 출력벡터는 Classifier의 입력 벡터로 들어가게 됩니다.
2.2 Multi-head Attention
2.3 Loss Function
1: 다음 문장인지 아닌지 예측
2 : Mask 단어 예측
total loss = 1+2
[Loss1] 다음 문장인지 아닌지 예측
- 첫번째 토큰인 [CLS] 토큰의 벡터만 사용한다.

[Loss2] mask 단어 예측





댓글