https://arxiv.org/pdf/1901.02860.pdf
오늘 소개할 Transformer XL은 ACL 2019에 발표된 논문으로, 기존의 Transformer 모델이 가지고 있는 ‘고정된 길이의 문맥(fixed-length context)'이라는 한계점을 개선하되 시간적인 일관성(temporal coherence)을 파괴하지 않는 선에서 새로운 아키텍처를 제시한 논문입니다.
이 논문의 저자는 유명한 언어모델인 XLNET과 정확히 동일한 저자들이 작성하였는데요, XLNET은 당시 2019년 20개 NLP task에서 bert를 넘어섰고, 18개 task에서 SOTA를 달성했습니다. XLNET의 프리퀄로 알려진 transformer-XL을 살펴보겠습니다.
1. 등장 배경
1) 언어모델에서의 오래된 과제 : 'Long-term dependency'
- 언어 모델링 분야에서 long-term dependency는 오랜기간 도전 과제였습니다. 이에 RNN과 LSTM의 등장으로 강력한 해결책이 등장하였고 다양한 벤치마크에서 좋은 성능을 거두었습니다. 하지만, RNN이 가진 치명적인 한계점이 있는데 그것은 gradient vanishing, exploding 문제로 최적화가 어렵다는 것이며, LSTM의 게이트로도 이 문제를 충분히 다루기 어려웠습니다. 실험적으로 LSTM은 평균 200개의 context word를 사용하는것으로 밝혀졌습니다.
2) 기존 Transformer 모델의 등장과 한계점
- 먼거리에 있는 단어간의 직접적인 연결(connection)을 long-term dependency를 해결하는 attention 메커니즘으로 long-term dependency를 학습할 수 있게 되었습니다.
- 논문이 나올 당시, AI-Rfou et all(2018)가 제안한 글자 단위(character-level)의 언어 모델링을 위해 깊은 트랜스포머를 쌓아 훈련한 모델이 등장하여 LSTM보다 큰 차이의 성능개선을 보였습니다. 하지만, 해당 모델은 약 100개 정도의 고정된 길이로 분리된 segment에서 학습되었고, 이는 segment간의 정보의 흐름이 없다는 것을 의미했습니다. 즉, 고정된 문맥길이 때문에 모델은 정해진 길이 이상의 longer-term dependency를 학습할수 없었습니다.
- 게다가 고정된 길이의 segment들은 어떤 의미상으로 경계지점을 나눈 것이 아니라 연속적인 symbol들의 뭉치를 선택하여 생성되어졌습니다. 이로인해 모델은 처음 등장하는 소수의 symbols을 예측하기위한 문맥적인 정보가 부족했고, 이는 낮은 성능으로 이어졌습니다. 이것이 바로 context fragmentation 문제입니다.
3) Transformer_XL 제안
- 앞서 언급한 고정된 길이의 문맥의 한계점들을 극복하기 위하여 Transformer_XL((extra long)을 제안하게 됩니다. 이 모델에서는 각 새로운 segment의 hidden state을 처음부터 계산하는것 이 아니라, 이전 segment에서 학습된 hidden state을재사용하여 segment들 간의 recurrent connection을 형성하였습니다. 이 recurrent connection을 따라서 정보가 전달되어 long-term dependency 를 학습할 수 있게 되며, 이전 segment로부터온 정보를 전달함으로써 context fragmentation 문제도 해결할 수 있게 됩니다.
- 또한 relative positional encodin을 사용하여, 시점의 혼란(temporal confusion)이 없이 state를 재사용할 수 있게 하였습니다.
- Transformer_XL은 단어 단위 에서 글자 단위까지 다양한 5개의 데이터셋에서 강력한 결과를 냈으며, 100M 개의 토큰을 학습하여, 상대적으로 일관된 약 100개의 토큰 길이의 긴 텍스트를 생성할 수 있었습니다.
- 이 논문의 기술적인 의의는 순수한 self-attentive 모델에서 recurrence 개념을 소개했다는 것과, 새로운 positional encoding 방법론을 이끌어냈다는 것에 있습니다. Transformer-XL은 문자단위와 단어단위에서 모두 RNN보다 좋은 성능을 기록한 첫번째 self-attention model입니다.
3. Model
3.1 Vanilla Transformer language Models
1) Train phase(학습)
- 트랜스포머 또는 self-attention을 언어모델에 적용하기 앞서 가장 핵심적인 문제는 '어떻게 트랜스포머가 임의의 긴 context를 고정된 크기의 representation으로 인코딩할 수 있는가?'입니다. 메모리와 컴퓨터 비용이 무한하다면 FFN(Feed Forward Neural Network)처럼 전체 context 시퀀스를 넣어서 트랜스포머 디코더로 처리하겠지만 보통의 경우, 실제 자원이 부족하여 실행 불가능합니다.
- 이때 하나의 가능한 대안은 전체 말뭉치를 작은 segment로 나누어서 각 segment 안에서만 모델을 학습하는 것입니다. 이때 이전 segment들이 가지고있는 문맥적인 정보는 무시하게됩니다. 이것을 Vanilla model이라고 하며 그림은 아래와 같습니다.

- 이때 정보는 정방향으로든 역방향으든 segments를 지나서 흘러갈수 없습니다. 이것은 2개의 치명적인 문제점을 가져옵니다.
1. dependency length는 segment의 길이로 최대값이 제한 됩니다
: 글자 단위의 모델에서는 수백개 정도에 해당합니다.
-> 비록 selft-attention 메카니즘으로 인해서 RNN에 비하여는 gradient vanishing의 영향이 적음에도 최적화 장점을 활용할 수 없습니다.
2. 의미상의 경계를 주거나 문장을 고려하기위하여 패딩을 사용하는것이 가능하지만, 실제로는 성능 문제로 인해서 긴 텍스트를 고정된 길이의 segment에 끼워넣는것이 일반적입니다. 단순히 시퀀스를 고정되 길이의 segments에 끼워넣는것은 context fragmentation 문제를 야기시킬수있습니다.
(2) Evaluation phase(평가)
- 평가 동안 바닐라 모델은 학습때와 동일한 길이의 segment를 사용하지만, 가장 마지막 위치의 토큰만을 예측합니다. 그리고 그 다음 단계에서는 하나의 위치한 이동(shift)하여 새로운 segmnet가 처음부터 다시 처리됩니다.
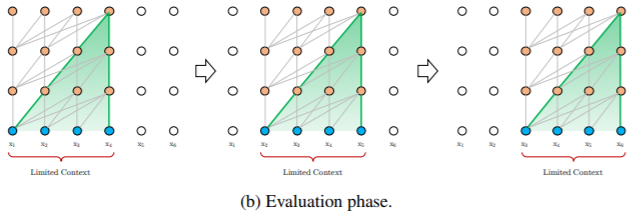
- 이 방법은 각 단계에서 학습 시 최대한의 길이의 정보를 활용할 수 있고 context fragmentation 이슈를 해결할 수 있지만, 많은 양의 계산량을 요구하고 속도가 느립니다.
3.2 Segment-Level Recurrence with State Reuse
- 고정된 길이의 context를 사용하는 한계점을 다루기위해서, Transformer 모델에 'reoccurence 메카니즘'을 소개하고자 합니다.
- 훈련 동안 이전 segment를 위해 계산된 hidden state 시퀀스는 고정되고 캐싱됩니다(cashed). 그리고 이후에 모델이 다음 segment를 학습할때에 extended context 의미로 재사용됩니다.
- 비록 gradient는 segment에 남아있지만, 이러한 추가적인 입력은 네트워크가 이전 history에 있는 정보를 활용하도록 하여 long-term dependency를 해결할 수 있고, context fragmetation을 해결할 수 있습니다.
'자연어처리(NLP) > LM(Language Model)' 카테고리의 다른 글
| [NLP][논문리뷰] XLNet: Generalized Autoregressive Pretrainingfor Language Understanding (1) | 2021.06.09 |
|---|---|
| [NLP][기초개념] 사전 훈련(Pre-training) 언어 모델 (0) | 2021.05.29 |
| [NLP][논문리뷰] ALBERT: A lite BERT for self-supervised learning of language representations (0) | 2021.05.29 |
| [NLP] BERT(버트) (0) | 2021.05.26 |




댓글