이번 글에서는 구글과 도요타에서 작년 2020년 ICLR에 발표한 논문인 'ALBERT: A lite BERT for self-supervised learning of language representations'에 대해서 리뷰하도록 하겠습니다.
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. However, at some point further model increases become harder due to GPU/TPU memory limitations and longer training times. To
arxiv.org
I will review a paper named ALBERT, A Lite BERT For self-supervised learning of language representation. It was proposed by Google and published at in ICLR in 2020.
As you may have noticed from the title, ALBERT is a variation of BERT. So before deep diving into ALBERT, We’ll take a look at the limitation of BERT and see how ALBERT overcomes it.

BERT was proposed by Google at 2018 and was able to achieve state-of-the-art performances on 11 separate NLP tasks. And a lot of different variations of language models are starting to dominate across various NLP tasks. Despite of the high performance, There are some important Limitations in BERT. One of the limitation is the monstrous size of models.
As you know, BERT-large model has 334 million parameters. It leads to memory limitation and long training time. If you wanted to build upon the work using BERT and bring improvements to it, you would require large computational costs to train. It is a big obstacle towards future research and deployability in real-world practice.
In addition, researchers have discovered that increasing the number of hidden layers in the BERT-large model can lead to even worse performance, which means ‘model degradation’. As you can see in the table, BERT large has better average score than BERT base, But When it comes to BERT xlarge average score decreases about 10 point compared to BERT large.
These obstacles motivated Google to take a deep dive into parameter reduction techniques that could reduce the size of models while not affecting their performance. ALBERT tried to overcome these limitations by three ideas.
1. Factorized embedding parameterization:
First Let’s look at factorized embedding parameterization.
In BERT, the embeddings size was linked to the hidden layer sizes of the transformer blocks. If we increase hidden units in the block, then we need to add a new dimension to each embedding as well.
From a practical point of view, natural language has a very large vocab size V, but if you match the size with H and E, the vocab embedding size (V X (times) E) becomes very large. Therefore, creating one more layer (E X H) that projects into the hidden space can further reduce the number of parameters. So, this reduced the number of parameters from O(V × H) to O(V × E + E × H). E is much smaller than H.
In general, the embedding layer has as many parameters as the total number of tokens (words) in the dictionary (V) * Word embedding dimension (E), O(V×E). This is about 23M in word embedding based on BERT-base with V=30000 and E=768, which is 21% of the total parameter 108M, accounting for a fairly large part.
After factorized embedding parameterization it has the number of parameters as O(V×E+E×H). This is about 4M based on V=30000, E=128, and H=768, which can be seen as about 1/6 of the existing method.
But can it be possible by maintaining performance?
From a modeling point of view,
BERT creates contextual embeddings through the Self-Attention Layer using word-level static embedding, WordPiece Embedding. WordPiece embedding learns a context-independent representation, and hidden layer embedding learns a context-dependent representation.
So researchers assume that a reduced size if word embedding doesn’t affect significantly to peformance. In conclusion, It allows us to grow the hidden size without significantly increasing the parameter size of the vocabulary embeddings.
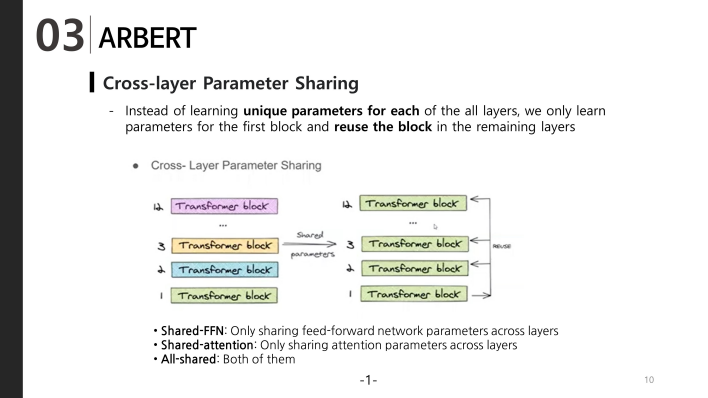
2. Cross-layer parameter sharing:
Seconds, Let’s look at Cross-layer parameter sharing.
BERT large model had 24 layers while it’s base version had 12-layers. As we add more layers, we increase the number of parameters exponentially. To solve this problem, ALBERT uses the concept of cross-layer parameter sharing. To illustrate, let’s see the example of a 12-layer BERT-base model. Instead of learning unique parameters for each of the 12 layers, we only learn parameters for the first block and reuse the block in the remaining 11 layers
We can share parameters for either feed-forward layer only, the attention parameters only or share the parameters of the whole block itself. The paper shares the parameters for the whole block.
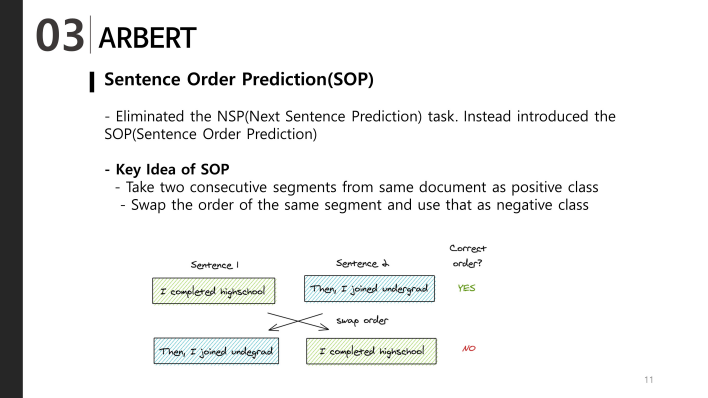
3. Sentence order prediction:
In the BERT paper, Google proposed a next-sentence prediction technique to improve the model’s performance in downstream tasks. However subsequent studies and papers like ROBERTA and XLNET found this to be unreliable.
That is : the sentence sees not only the continuity, but also the topic of the sentence. If it is a randomly selected sentence model, it may be judged as a negative example by the different topic of the sentence.
the author improved this and proposed Sentence order prediction (SOP). The method is very simple, that is, the original predicted sentences are replaced in order.
The key idea is:
1. Take two consecutive segments from the same document as a positive class
2. Swap the order of the same segment and use that as a negative example
This forces the model to learn finer-grained distinction about discourse-level coherence properties.
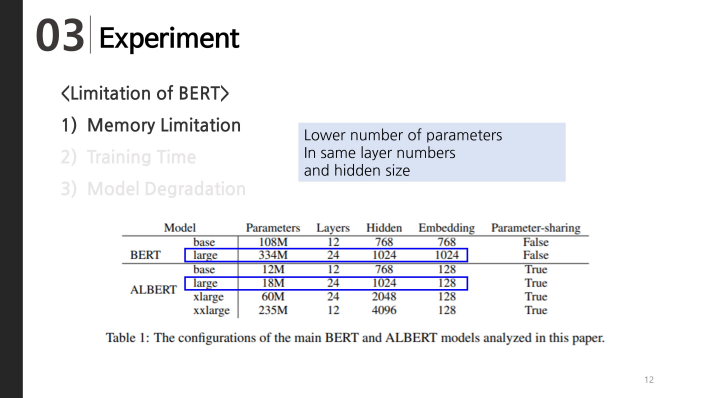
Experiment
Now It’s the experiment of this paper. Focusing on how limitation of BERT were improved Let’s see the results.
First limitation of BERT was memory limitation. As you can see in this table, BERT large and ALBERT-large has same number of layers and same hidden size. However, the number of parameters in ALBERT-large is 18 times smaller than BERT large
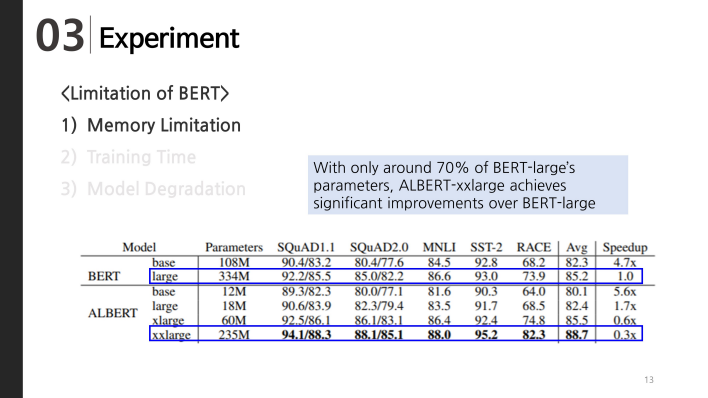
Then. What about performance? Let's compare when the number of parameters is similar. Look at the BERT-large and ALBERT-xxlarge in this table. ALBERT-xx-large Has lower number of parameters than BERT-large. But average score is higher than BERT-large by about 2 point.
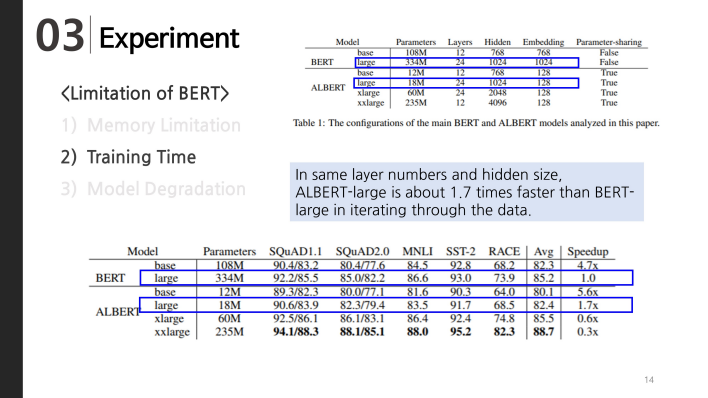
And Second limitation of BERT was training time.
In this table, Let’s see the ALBERT-large and BERT-large which have same layer numbers and hidden size. ALBERT-large is about 1.7 times faster than BERT-large in iterating through the data.
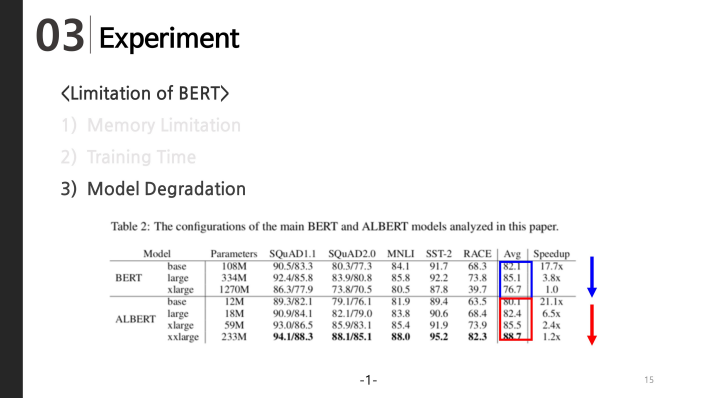
And Third limitation of BERT was model degradation.
While BERT performance degrades when it grows from large to xlarge. However, for ALBERT, xxlarge outperforms xlarge and xlarge outperforms large.
Of course, if ALBERT continues to increase the hidden size and number of layers, the performance will decrease. According to the paper, when the hidden size is 6144, the performance is lower than when it is 4096.
However, in ALBERT, even the xxlarge model which is larger than BERT xlarge does not cause model degradation, so we can assume higher performance can be obtained for various downstream tasks.
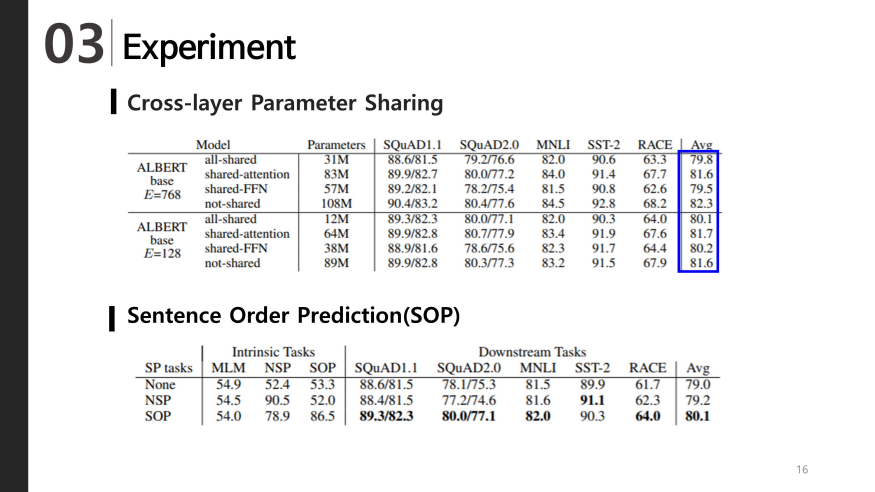
Parameter sharing
Next we will see the effect of Parameter sharing
As shown in the table below, sharing only the Self-Attention Layer does not significantly degrade performance. However, you may find that the FFN (Feed Forward Network) performs somewhat lower when sharing.
Sentence Prediction
The table below compares the performance of NSP and SOP training on ALBERT. When learning with NSP, NSP does not learn the relationship between sentences well. so SOP performance is very low. In addition, it can be seen that the performance is higher when SOP is applied in tasks such as SQuAD, MNLI, and RACE that are performed by putting two or more sentences as input.

Conclusion
ALBERT uses two optimizations to reduce model size: a factorization of the embedding layer and parameter-sharing across the hidden layers of the network.
In addition, the suggested approach includes a self-supervised loss for sentence-order prediction to improve inter-sentence coherence.
With the introduced parameter-reduction techniques, the ALBERT configuration with 18× fewer parameters and 1.7× faster training compared to the original BERT-large model achieves only slightly worse performance.
- The much larger ALBERT configuration, which still has fewer parameters than BERT-large, outperforms all of the current state-of-the-art language modes by getting the score like this
[ALBERT에 대한 학생들의 질문]
1. parameters을 줄이기 위해서 tranformer block을 sharing했다고 이해했습니다. 그런데 이러면 동일한 weights을 계속해서 곱하는 것 (일반적으로는 각 layer마다 다른 weights을 주어서 추출하는 pattern이 다르게 구성)인데 왜 기존 BERT와 유사할 수 있는 것인지 궁금합니다.
2. ALBERT에서 파라미터를 share한다는 부분 좀더 설명부탁드려도될까요?!
3. 해당 논문에서 사용된 decomposition 기법은 제가 이해하기로는 bottleneck block처럼 channel수를 줄여 computation을 아끼는 기존 방법들과 매우 흡사한 것처럼 보이는데요, 기존 효율성을 타게팅한 논문들이 다양한 실험을 통해서 최적의 값을 찾아낸것과 같이 128 —> 768외에도 grouped convolution처럼 group을 쪼갠 뒤 concat하는 식의 기법들처럼 computation을 줄이는 다른 방향으로의 실험이 있을까요?
4. When only attention is shared, the performance is higher than when all shared. Why does the performance decrease when ffn is shared?
5. Did they use same sentences(or dataset) for SOP as NSP? Or use a novel dataset?
6. 14쪽에 xalbert의 학습속도가 기존 버트보다 더 느리게 나오는데 파라미터 수는 적은데 왜 속도가 더 느리나요? 학습방법이 더 어렵나요?
7. V X H 대신 Vx E + E xH 로 해서 파라미터 수가 줄어들었는데 혹시 특정하게 학습에 좋다고 정해진 E 값이 있나요?
8. Does sentence order prediction task requires predicting the order between two sentence pair? Why different result from NSP? Seems so similar.
9. bert에서는 layer마다 서로 다른 정보를 encoding하는 것으로 알고 있는데 parameter sharing을 했을 때 작동하는 방식 차이에 대한 언급이 있나요?
10. In Table 4(CROSS-LAYER PARAMETER SHARING), what do you think of the reason of the result that "shared-attention" performs the best among cross-layer parameter sharing settings (and comparable with "not-shared" in ALBERT base E=128 setting)?
11. Why does pretraining model using SOP tasks yield better performance in a wide range of downstream tasks compared to NSP tasks?
12. 4페이지에서 BERT와는 달리 H보다 E가 작게 설정된 것을 볼 수 있는데, 그 이유가 무엇인가요??
13. What is the difference between ALBERT-base(E=768, not-shared) and BERT-base? (파라미터 수는 같은 것처럼 보이는데요) 저는 16페이지 첫번째 표랑 15페이지? 표를 참고했습니다 감사합니다
14. albert xxlarge model의 경우 bert large보다 parameter가 적은데 훈련시간이 더 오래걸리는 이유가 있을까요?
좋아요공감
공유하기
통계
글 요소
<그외>
1. 다른 BERT variations
- https://analyticsindiamag.com/top-ten-bert-alternatives-for-nlu-projects/
'자연어처리(NLP) > LM(Language Model)' 카테고리의 다른 글
| [NLP][논문리뷰] Transformer-XL: Attentive Language ModelsBeyond a Fixed-Length Context (0) | 2021.06.09 |
|---|---|
| [NLP][논문리뷰] XLNet: Generalized Autoregressive Pretrainingfor Language Understanding (1) | 2021.06.09 |
| [NLP][기초개념] 사전 훈련(Pre-training) 언어 모델 (0) | 2021.05.29 |
| [NLP] BERT(버트) (0) | 2021.05.26 |




댓글