https://arxiv.org/pdf/1906.08237.pdf
<요약>
최근 양방향 컨텍스트에 대한 모델링이 가능해짐과 함께, BERT와 같은 Denoising autoencoding 기반의 사전학습 방식은 Auto-regressive 언어 모델링 기반의 사전학습 방식보다 더 나은 성능을 달성하였습니다. 그러나 BERT의 경우 마스크로 입력값을 손상시켜 학습해야만 하는데, 이는 마스크 된 토큰들 간의 dependency를 반영하지 못하며, 또한 pretrain에 존재하는 [MASK] 심볼이 실제 데이터로 finetune할때는 존재하지 않는다는 문제도 존재합니다. 저자는 이러한 AR과 AE의 장단점을 고려한 Auto-regressive 사전훈련 방법인 XLNet을 제안하였습니다.
(1) factorization order의 모든 순열에 대하여 예측된 likelihood을 최대화하여 양방향 컨텍스트 학습을 가능하게함
(2) Auto-regressive를 통해 덕분에 BERT의 한계를 극복
(3) state-of-the-art Auto-regressive모델인 Transformer-XL의 아이디어를 사전 훈련에 통합
XLNet은 질문 답변, 자연어 추론, 감정 분석 및 문서 순위를 포함하여 20 개 작업에서 BERT보다 좋은 성능을 기록합니다.
<Background 개념>
1. Unsupervised representation learning
Unsupervised representation learning은 NLP 분야에서 좋은 성과를 내고 있습니다. 전형적인 방법은 먼저 방대한 양의 unlabeled된 텍스트 말뭉치로 신경망을 사전학습한 후 downstream work에 맞게 모델이나 representation을 파인튜닝(finetune)하는 것입니다. 여기서 AR(Auto-regressive)와 AE(Auto-encoding) 방식이 가장 성공적인 사전학습 방법의 두 유형이라고 할 수 있습니다.
1.1 AR(Auto-regressive/자기회귀)
: AR 언어모델은 일반적인 언어모델의 학습 방법으로 이전 token들을 보고 다음 token을 예측하는 문제를 풉니다.
: 텍스트 시퀀스가 주어졌을 때, likelihood를 아래와 같이 forward product하거나 backward product를 하여 분해합니다.
| text sequence |  |
|
| likelihood | forward-product | 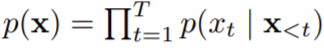 |
| backward-product |  |
|
| objective (forward) |  |
|
신경망과 같은 parametric model은 각각의 조건부 분포를 모델링하도록 학습됩니다.
[단점] not effective at modeling deep bidirectional context
AR 언어모델이 단방향 컨텍스트(forward 또는 backward)를 인코딩하기 위하여 훈련되기 때문에 깊은 양방향 컨텍스트를 모델링하기에는 효과적이지 않습니다. 하지만 downstream 과제들은 종종 양방향 컨텍스트 정보를 요구합니다. 이러한 점 때문에 AR 언어모델과 효과적인 사전학습은 조금 부합하지 않아 보입니다.
1.2 AE(Auto-Encoding)
| objective |  |
|
[장점] bidirectional information
- AR과 달리 AE를 기반으로한 사전학습은 분포를 추정하지 않고 손상된 데이터를 원래 데이터로 재건(reconstruct)하는 것을 목표로 합니다. 가장 대표적인 예시는 BERT입니다 입니다. 주어진 입력 시퀀스에서 특정한 비율의 토큰들은 특정 심볼인 [MASK]로 대체되고, 모델은 손상된 버전에서 원래의 토큰을 복구하도록 학습됩니다.
- BERT는 목적함수에 분포를 추정하는것이 없기 때문에 재건(reconstruction)을 위해서 양방향 컨텍스를 활용하는것이 가능해집니다. 즉, 앞서 말한 AR 언어 모델이가진 양방향 정보의 부재를 해결하고 성능을 개선할수 있습니다.
[단점] pretrain-finetune discrepancy
- 하지만 BERT에서 사전학습 시 사용되는 [MASK]와 같은 인공적인 심볼은 실제 데이터를 파인튜닝할때에는 존재하지 않습니다. 이로 인해서 'pretrain-finetune discrepancy' 문제가 발생하게 됩니다.
- 게다가 예측되는 토큰들은 입력값에 마스킹이 되기 때문에, BERT에서는 AR언어모델과 같이 product rule을 사용하여 조건부 확률을 모델링할수 없습니다. 이 말은 즉, BERT에서는 예측되는 토큰들은 서로 독립적이라는 가정을 해야 합니다. 이것은 자연어처리분야에서 만연한 high-order, long-range dependency 특성을 단순화시켜 버리게 되죠.
이와같이 기존 언어 사전학습 유형의 장단점을 따라 논문에서는 AR 언어모델과 AE를 단점을 개선하고 장점을 극대화한 일반화된 Autoregressive model을 제안하였습니다.
<장단점 비교>
| 단점/장점 | AR(Auto-Regressive) | AE(Auto-Encoding) |
| Independence Assumption | X | O (모든 마스킹된 토큰들은 서로 독립적이라고 가정) |
| Input noise (pretrain-finetune descrepancy) |
X | O (BERT) [MASK]를 노이즈로 추가 |
| Context dependency | X (단방향만 가능) |
O (BERT는 양방향 문맥정보를 다룰 수 있음) |
2. 방법론
2.1 Objective: Permutation Language Modeling
: AR모델의 장점을 유지하되, 양방향 컨텍스트를 확보할 수 있도록 하는 모델.
- 길이가 T인 시퀀스 x에는 T!개의 서로다른 순서가 autoregressive factorization을 위해 존재합니다. 직관적으로 만약 모델 파라미터들이 모든 factorization roders에 대하여 공유된다면, 모델은 양방향의 모든 위치에서 정보를 얻을 수 있도록 학습될 것입니다. (자기 자신이 아닌 모든 단어에 대하여 참조)
=> independence assumption과 pretrain-finetune descrepancy 문제 해결

- x : 텍스트 시퀀스
- z : factorization order
- Z(T) : 길이가 t인 시퀀스의 모든 가능한 순열조합들
- Θ : 모델 파라미터(공유됨)
| ※ 주의사항 - 순열의 대상이 되는 것은 sequence order가 아니라 factorization order입니다! - 원래의 sequnce order는 positional encoding을 사용해서 유지합니다. (??) 그럼 위에서 말한 순열은 도대체 무엇의 순서를 섞은 것일까요? -> Transformer의 attention mask에서 순서를 바꾸는 순열이 사용이 됩니다. - finetuning 을 하는 동안에는 있는 그대로 순서의 텍스트 시퀀스만 다룰 것이기 때문에 이러한 선택(sequence order는 그대로 보존하고 Transforme의 attention mask단의 Factorization order의 순서를 바꿈)은 필수적임! |
2.2 Architecture: Two-Stream Self-Attention for Target-Aware Representations
- 하지만 논문에서 제시하는 방법은, Standard Transformer parameterixation에서는 작동하지 않습니다.

- 이 문제를 살펴보기 위해서, 우리가 다음 토큰의 분포(p(Θ)를 parameterize 하기위해 standard 소프트맥스 공식을 쓴다고 해봅시다.

- hΘ(X z<t)은 마스킹 후 공유된 Transformer 네트워크를 통해 생성된 X z<t의 hidden representation으로, 예측할 단어의 위치 zt에 의존하지 않습니다. 결과적으로, target 위치에 상관없이 같은 분포가 예측되기 때문에 유용한 representation을 학습할 수 없다. 이런 문제를 피하기 위해서 논문에서는 아래와 같이 target 위치를 인식하기 위해 아래와 같이 다음 토큰의 분포를 re-parameterize 하는 것을 제안합니다.

- gΘ(X z<t, zt) 는 target position인 zt를 추가적으로 입력값으로 받는 새로운 유형의 representation입니다.
*Two-Stream Self-Attention
- target-aware representaiton 아이디어는 target 예측에 있어서 모호함을 없애주는 반면, gΘ(X z<t, zt) 를 어떻게 계산할 것인가는 또다른 문제로 남아있습니다. 이를 위하여 standard Transformer 아키텍처와 모순되는 2가지 요구사항이 존재합니다.
1) 토큰 x (zt) 와 gΘ(X z<t, zt)을 예측하기 위해서는 zt의 위치만 사용하고, x(zt)의 내용은 사용해서는 안된다.
2) 다른 토큰 x(zj)를 예측할때(j>t), 전체 문맥 정보를 제공하기 위해서는 gΘ(X z<t, zt)가 반드시 x (zt)를 인코딩해야한다.
이러한 문제를 해결하기 위해서 1개가 아닌 2개의 hidden representation을 제안합니다.
| content representation |  |
Standard 트랜스포머의 hidden state과 같은 역할로, 문맥과 x(zt)자기자신을 인코딩 |
| query representation |  |
X(z<t)와 위치 zt에 대한 문맥 정보에 접근할수 있으며 x(zt)의 정보는 없음 |
- 각 self attention layer마다 2개의 representation이 공유된 파라미터 셋을 가지고 업데이트 됩니다.

2.4 Incorporating Ideas from Transformer-XL
| maximize the expected likelihood over all pemutaion of factorization order | - 전통적인 AR모델에서와 같이 고정된 forward 또는 backward factorization order을 사용하지 않고, factorization order의 모든 가능한 순열의 log likelihood 예측값을 최소화하도록 학습 - 순열로 인해서 각 토큰의 문맥은 왼쪽 오른쪽 양방향에 있는 토큰들로 구성될 수 있습니다. 각 위치의 토큰들은 모든 위치로부터 문맥 정보를 활용할 수 있도록 학습합니다. -> capturing bidirectional context |
| autoregressive model | AR 모델을 일반화하여 손상된 데이터에만 의존하지 않습니다. -> capturing pretrain-finetune discrepancy autoregressive objective는 예측하는 토큰에 대한 조건부 확률을 분해하여 product rule을 수행할 수 있기 때문에 BERT가 가지고 있었던 독립 가정을 없앨 수있습니다. -> eliminate the independence designs for pretraining |
| Transformer-XL | 1) segment recurrence 2) relative positional encoding |
'자연어처리(NLP) > LM(Language Model)' 카테고리의 다른 글
| [NLP][논문리뷰] Transformer-XL: Attentive Language ModelsBeyond a Fixed-Length Context (0) | 2021.06.09 |
|---|---|
| [NLP][기초개념] 사전 훈련(Pre-training) 언어 모델 (0) | 2021.05.29 |
| [NLP][논문리뷰] ALBERT: A lite BERT for self-supervised learning of language representations (0) | 2021.05.29 |
| [NLP] BERT(버트) (0) | 2021.05.26 |




댓글